近年、大規模言語モデル (LLM) はさまざまな分野で驚くべき能力を発揮していますが、その数学的推論能力は驚くほど弱いです。 Downcodes の編集者が、算術演算における LLM の驚くべき「秘密」を明らかにする最新の研究を解釈し、この方法の限界と将来の改善の方向性を分析します。この研究は、LLM の内部動作メカニズムについての理解を深めただけでなく、LLM の数学的機能を向上させるための貴重な参考資料も提供します。
最近、AI 大型言語モデル (LLM) は、詩を書いたり、コードを書いたり、チャットしたりするなど、さまざまなタスクで優れたパフォーマンスを発揮しています。しかし、これらの「天才」AI は、実は「数学の新人」だということが信じられますか?単純な算数の問題を解くときによくひっくり返りますが、これは驚くべきことです。
最新の研究により、LLM の算術推論能力の背後にある「奇妙な」秘密が明らかになりました。LLM は、強力なアルゴリズムにもメモリにも依存せず、「ヒューリスティックごった煮」と呼ばれる戦略を採用しています。これは、数式や定理を真剣に勉強していない学生のようなものです。しかし、答えを得るには「ちょっとした賢さ」と「経験則」に頼っています。
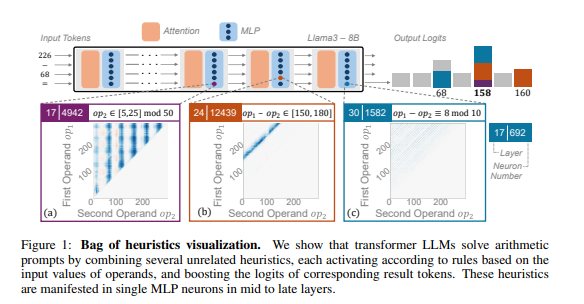
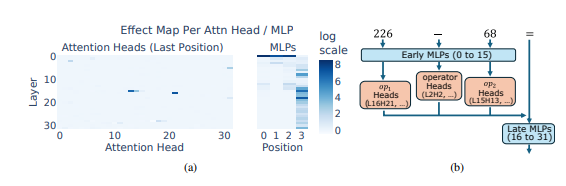
研究者らは、典型的なタスクとして算術推論を使用し、Llama3、Pythia、GPT-J などの複数の LLM の詳細な分析を実施しました。彼らは、算術計算を担当する LLM モデルの部分 (「回路」と呼ばれる) が多数の個別のニューロンで構成されており、それぞれが「小型計算機」のように機能し、特定の数値パターンを認識して対応する数値を出力することだけを担当していることがわかりました。答え。 たとえば、あるニューロンは「1 桁が 8 である数字」の識別を担当し、別のニューロンは「結果が 150 から 180 の間になる減算演算」の識別を担当する可能性があります。
これらの「ミニ電卓」はツールをごちゃ混ぜにしたようなもので、特定のアルゴリズムに従ってツールを使用するのではなく、LLM はこれらの「ツール」をランダムに組み合わせて、入力された数値のパターンに基づいて答えを計算します。 それは、シェフが決まったレシピを持たず、手元にある材料をもとに気の向くままに調合し、最終的に「闇の料理」を作るようなものです。
さらに驚くべきことは、この「ヒューリスティックごった煮」戦略が実際に LLM トレーニングの初期段階に現れ、トレーニングが進むにつれて徐々に改善されていったということです。これは、LLM が、後の段階でこの戦略を開発するのではなく、最初から推論に対するこの「パッチワーク」アプローチに依存していることを意味します。
では、この「奇妙な」算術推論方法はどのような問題を引き起こすのでしょうか? 研究者らは、「ヒューリスティックごった煮」戦略には一般化能力が限られており、エラーが発生しやすいことを発見しました。 なぜなら、LLM には限られた数の「小さな賢さ」があり、その「小さな賢さ」自体にも、新しい数値パターンに遭遇したときに正しい答えを出せない欠陥がある可能性があるからです。 「トマトのスクランブルエッグ」しか作れない料理人のように、突然「魚風味豚細切り」を作れといわれたら、きっと慌てて途方に暮れるだろう。
この研究により、LLM の算術推論能力の限界が明らかになり、今後の LLM の数学能力向上の方向性も指摘されました。 研究者は、既存のトレーニング方法とモデル アーキテクチャだけに依存するだけでは LLM の算術推論能力を向上させるのに十分ではない可能性があり、LLM が真の「数学マスター」になれるよう、より強力で一般的なアルゴリズムを学習するのに役立つ新しい方法を探索する必要があると考えています。
論文アドレス: https://arxiv.org/pdf/2410.21272
全体として、この研究は、数学的推論における LLM の「奇妙な」戦略の詳細な分析を提供し、LLM の限界を理解するための新しい視点を提供し、将来の研究の方向性を示しています。テクノロジーの継続的な発展により、LLM の数学的能力は大幅に向上すると私は信じています。