Downcodes の編集者は、北京大学と他の科学研究チームが画期的なマルチモーダル オープンソース モデルである LLaVA-o1 をリリースしたことを知りました。このモデルは、複数のベンチマーク テストで Gemini、GPT-4o-mini、Llama などの競合製品を上回り、その「遅い思考」推論メカニズムにより、GPT-o1 に匹敵するより複雑な推論を実行することができました。 LLaVA-o1 のオープンソースは、マルチモーダル AI 分野の研究と応用に新たな活力をもたらすでしょう。
最近、北京大学とその他の科学研究チームは、LLaVA-o1 と呼ばれるマルチモーダル オープンソース モデルのリリースを発表しました。これは、GPT-o1 に匹敵する、自発的かつ体系的な推論が可能な初の視覚言語モデルと言われています。
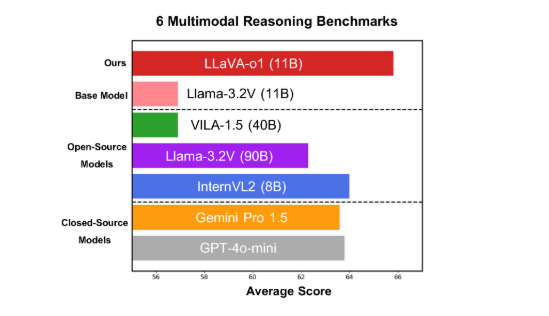
このモデルは、6 つの困難なマルチモーダル ベンチマークで良好なパフォーマンスを示し、11B パラメーター バージョンは、Gemini-1.5-pro、GPT-4o-mini、Llama-3.2-90B-Vision-Instruct などの他の競合製品を上回っています。
LLaVA-o1 は Llama-3.2-Vision モデルに基づいており、従来の思考連鎖プロンプト方式を超え、より複雑な推論プロセスを独立して実行できる「遅い思考」推論メカニズムを採用しています。
マルチモーダル推論ベンチマークでは、LLaVA-o1 は基本モデルを 8.9% 上回りました。このモデルは、推論プロセスが要約、視覚的説明、論理的推論、結論生成の 4 つの段階に分かれているという点で独特です。従来のモデルでは推論プロセスが比較的単純であることが多く、誤った答えにつながりやすいのに対し、LLaVA-o1 は構造化された複数ステップの推論を通じてより正確な出力を保証します。
たとえば、「明るい小さなボールと紫色のオブジェクトをすべて差し引いた後、オブジェクトはいくつ残るでしょうか?」という問題を解く場合、LLaVA-o1 はまず問題を要約し、次に画像から情報を抽出し、ステップバイステップの推論を実行します。 、そして最後に答えを与えます。この段階的なアプローチにより、モデルの体系的な推論機能が向上し、複雑な問題をより効率的に処理できるようになります。

LLaVA-o1 では、推論プロセスにステージレベルのビーム探索手法が導入されていることに言及する価値があります。このアプローチにより、モデルは各推論段階で複数の候補回答を生成し、最良の回答を選択して推論の次の段階に進むことができるため、全体的な推論の品質が大幅に向上します。教師付き微調整と合理的なトレーニング データにより、LLaVA-o1 は大規模なモデルやクローズドソース モデルと比較して優れたパフォーマンスを発揮します。
北京大学チームの研究結果は、マルチモーダル AI の開発を促進するだけでなく、将来の視覚言語理解モデルに新しいアイデアと手法を提供します。チームは、LLaVA-o1 のコード、事前トレーニング重み、およびデータセットは完全にオープンソースになると述べ、より多くの研究者と開発者が共同でこの革新的なモデルを探索し、適用することを期待していると述べています。
論文: https://arxiv.org/abs/2411.10440
GitHub:https://github.com/PKU-YuanGroup/LLaVA-o1
LLaVA-o1 のオープンソースは、間違いなくマルチモーダル AI 分野における技術開発とアプリケーションの革新を促進します。その効率的な推論メカニズムと優れたパフォーマンスは、今後の視覚言語モデル研究の重要な参考資料となり、注目と期待に値します。私たちは、より多くの開発者が参加し、人工知能技術の進歩を共同で促進することを楽しみにしています。