オープンソースAI分野は近年活況を呈しているが、大手テクノロジー企業と比べるとまだ差がある。コンピューティング能力は 1 つの側面にすぎません。より重要な側面は、トレーニング後のソリューションが不足していることです。 AI2 (旧アレン人工知能研究所) の最新の画期的な Tülu3 ポストトレーニング プログラムは、このギャップを埋めるための強力な武器を提供します。 Downcodes のエディターでは、このテクノロジーがどのようにオープンソース AI を強化し、元々制御が困難だった大規模な言語モデルを使いやすくカスタマイズできるようにする方法について深く理解できます。
オープンソース AI の分野では、大手テクノロジー企業との差はコンピューティング能力に反映されるだけではありません。 AI2 (旧称 Allen Artificial Intelligence Institute) は、一連の画期的な取り組みを通じてこのギャップを埋めており、新しくリリースされた Tülu3 ポストトレーニング プログラムにより、オリジナルの大規模言語モデルを実用的な AI システムに変換することが可能になります。
一般的な認知とは異なり、基本的な言語モデルは事前トレーニング後に直接使用することはできません。実際、トレーニング後のプロセスは、モデルの最終的な価値を決定する重要な要素です。この段階で、モデルは判断力を欠いた全知のネットワークから、特定の機能指向を備えた実用的なツールに変わります。
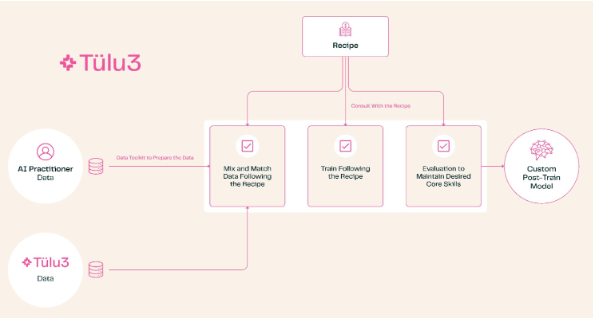
大手企業は長い間、研修後のプログラムについては秘密にしてきました。最新のテクノロジーを使用すれば誰でもモデルを構築できますが、心理カウンセリングや研究分析などの特定の分野でモデルを役立つようにするには、独自のトレーニング後のテクニックが必要です。オープンソースとして宣伝されている Meta's Llama のようなプロジェクトであっても、その元のモデルのソースと一般的なトレーニング方法は依然として極秘です。
Tülu3 の登場により、この状況は変わります。このトレーニング後ソリューションの完全なセットは、トピックの選択からデータ管理、強化学習から微調整まで、あらゆるプロセスをカバーします。ユーザーは、数学やプログラミングの機能を強化したり、多言語処理の優先順位を下げたりするなど、ニーズに応じてモデルの機能を調整できます。
AI2 のテストでは、Tülu3 によってトレーニングされたモデルのパフォーマンスがトップのオープンソース モデルのレベルに達していることが示されています。この画期的な進歩は重要であり、企業に完全に自律的で制御可能な選択肢を提供します。特に医学研究などの機密データを扱う機関では、サードパーティの API やカスタマイズされたサービスに依存する必要がなくなり、トレーニング プロセス全体をローカルで完了できるため、コストが節約され、プライバシーが保護されます。
AI2 はこのソリューションをリリースしただけでなく、自社製品への適用も率先して行いました。現在のテスト結果は Llama モデルに基づいていますが、独自の OLMo に基づいて Tülu3 によってトレーニングされた新しいモデルを立ち上げる計画があり、これは最初から最後まで真に完全なオープンソース ソリューションになります。
このオープンソース テクノロジーは、AI の民主化を促進するという AI2 の決意を示すだけでなく、オープンソース AI コミュニティ全体に活気を与えます。これにより、真にオープンで透明な AI エコシステムに一歩近づくことができます。
Tülu3 のオープンソースは、オープンソース AI の分野における大きな前進を示し、AI アプリケーションの敷居を下げ、AI テクノロジーの公平性と共有を促進し、将来の AI 開発に無限の可能性をもたらします。 私たちは、より繁栄した AI エコシステムを共同で構築するために、より類似したオープンソース プロジェクトが出現することを期待しています。