Downcodes エディターのレポート: 近年、オーディオ駆動の画像アニメーション技術が急速に発展していますが、既存のモデルには効率と持続時間の点で依然としてボトルネックがあります。この問題を解決するために、研究者らは JoyVASA と呼ばれる新技術を開発しました。この技術は、独創的な 2 段階の設計により、オーディオ駆動の画像アニメーションの品質と効率を大幅に向上させます。 JoyVASA は、より長いアニメーション ビデオを生成できるだけでなく、動物の顔のアニメーションをサポートし、優れた多言語互換性を示し、アニメーション制作の分野に新たな可能性をもたらします。
最近、研究者らは、オーディオ主導の画像アニメーション効果を向上させることを目的とした、JoyVASA と呼ばれる新しいテクノロジーを提案しました。ディープラーニングと拡散モデルの継続的な開発により、オーディオ主導のポートレート アニメーションはビデオ品質とリップ シンクの精度において大幅な進歩を遂げました。ただし、既存のモデルの複雑さにより、トレーニングと推論の効率が向上する一方で、ビデオの継続時間とフレーム間の連続性も制限されます。
JoyVASA は 2 段階の設計を採用しています。最初の段階では、動的な顔の表情を静的な 3 次元の顔の表現から分離するための分離された顔の表現フレームワークが導入されています。
この分離により、システムは静的な 3D 顔モデルと動的なアクション シーケンスを組み合わせて、より長いアニメーション ビデオを生成できるようになります。第 2 フェーズでは、研究チームは、音声キューからアクション シーケンスを直接生成できる拡散トランスフォーマーをトレーニングしました。これは、キャラクターのアイデンティティに依存しないプロセスです。最後に、第 1 段階のトレーニングに基づくジェネレーターは、3D 顔表現と生成されたアクション シーケンスを入力として受け取り、高品質のアニメーション効果をレンダリングします。
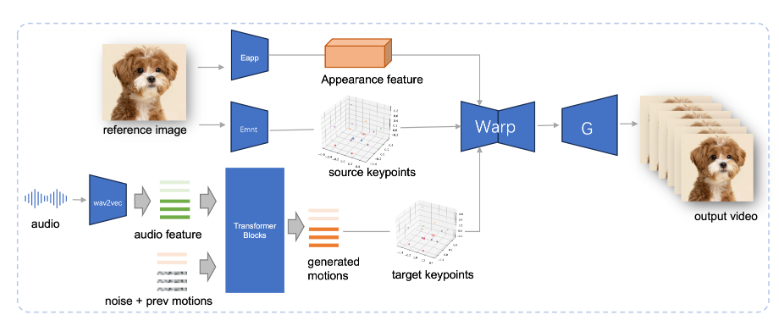
特に、JoyVASA は人間のポートレートのアニメーションに限定されず、動物の顔をシームレスにアニメーション化することもできます。このモデルは、中国語のプライベート データと英語のパブリック データを組み合わせた混合データ セットでトレーニングされており、優れた多言語サポート機能を示しています。実験結果はこの方法の有効性を証明しており、今後の研究は、画像アニメーションにおけるこのフレームワークの適用をさらに拡大するために、リアルタイム性能の向上と表現制御の改良に焦点を当てていきます。
JoyVASA の出現は、オーディオ駆動アニメーション技術における重要な進歩を示し、アニメーション分野における新たな可能性を促進します。
プロジェクト入口: https://jdh-algo.github.io/JoyVASA/
JoyVASA テクノロジーの革新性は、効率的な 2 段階の設計と強力な多言語サポート機能にあり、アニメーション制作により便利で効率的なソリューションを提供します。今後、さらなる技術の向上により、JoyVASAはより多くの分野で活用され、よりリアルで刺激的なアニメーション作品を私たちにもたらしてくれることが期待されます。さらなる技術の進歩とアニメーション業界の発展の新たな章をリードすることを楽しみにしています!