Downcodes の編集者は、Meta が最近、能力評価ベンチマーク テスト Multi-IF に続き、新しい多言語マルチターン ダイアログ コマンドをリリースしたことを知りました。このベンチマークは 8 つの言語をカバーし、4501 の 3 ラウンドのダイアログ タスクが含まれており、大規模な評価をより包括的に行うことを目的としています。実際のアプリケーションにおける言語モデル (LLM) のパフォーマンス。主にシングルターンの対話と単一言語のタスクに焦点を当てた既存の評価基準とは異なり、Multi-IF は複雑なマルチターンおよび複数言語のシナリオにおけるモデルの能力を調べることに焦点を当てており、LLM の改善のためのより明確な方向性を提供します。
Meta は最近、Multi-IF と呼ばれる新しいベンチマーク テストをリリースしました。これは、マルチターン会話および多言語環境における大規模言語モデル (LLM) の命令追従能力を評価するように設計されています。このベンチマークは 8 つの言語をカバーし、複雑なマルチターンおよび複数言語のシナリオにおける現在のモデルのパフォーマンスに焦点を当てた 4501 の 3 ターン対話タスクが含まれています。
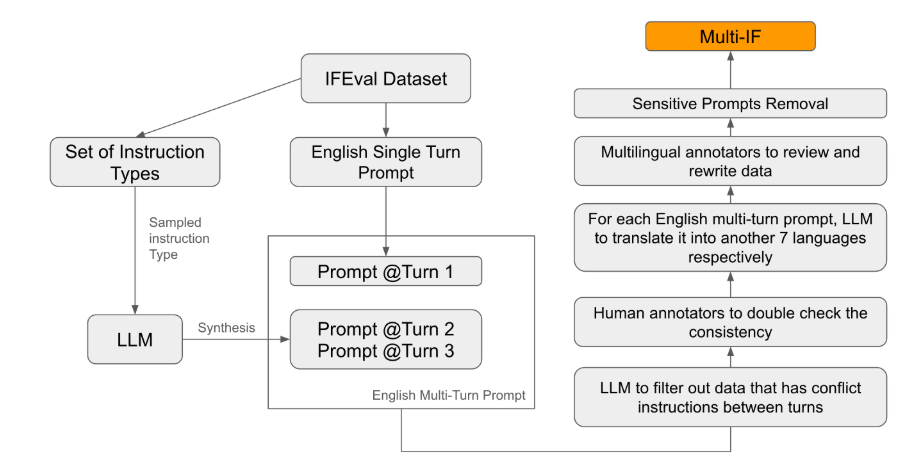
既存の評価基準の多くは、シングルターン対話や単一言語タスクに重点を置いており、モデルの性能を実際のアプリケーションに完全に反映することが困難です。 Multi-IF の導入は、このギャップを埋めるためのものです。研究チームは、単一ラウンドの指示を複数ラウンドの指示に拡張することで複雑な対話シナリオを生成し、各ラウンドの指示が論理的に一貫性があり、進歩的であることを確認しました。さらに、データセットは自動翻訳や手動校正などの手順を通じて多言語サポートも実現します。
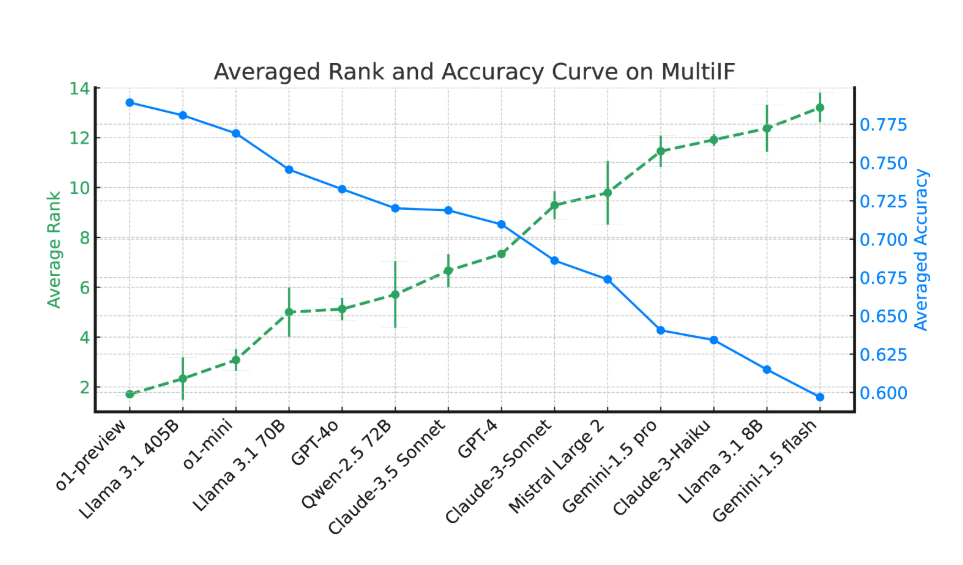
実験結果によると、ほとんどの LLM のパフォーマンスは、複数の対話ラウンドにわたって大幅に低下します。 o1-preview モデルを例にとると、第 1 ラウンドの平均精度は 87.7% でしたが、第 3 ラウンドでは 70.7% に低下しました。特にヒンディー語、ロシア語、中国語などの非ラテン文字を使用する言語では、モデルのパフォーマンスが一般的に英語よりも低く、多言語タスクでの限界が示されています。
14 の最先端の言語モデルの評価では、o1-preview と Llama3.1405B が最高のパフォーマンスを示し、3 ラウンドの命令でそれぞれ平均精度率が 78.9% と 78.1% でした。しかし、複数ラウンドの対話を通じて、すべてのモデルは指示に従う能力の全体的な低下を示し、これは複雑なタスクでモデルが直面する課題を反映しています。研究チームはまた、複数ラウンドの対話におけるモデルの命令忘れ現象を定量化するために「命令忘れ率」(IFR)を導入し、その結果、高性能モデルはこの点で比較的良好なパフォーマンスを示した。
Multi-IF のリリースは、研究者に挑戦的なベンチマークを提供し、グローバリゼーションおよび多言語アプリケーションにおける LLM の開発を促進します。このベンチマークの開始により、複数ラウンドおよび複数言語のタスクにおける現在のモデルの欠点が明らかになるだけでなく、将来の改善の明確な方向性も示されます。
論文: https://arxiv.org/html/2410.15553v2
Multi-IF ベンチマーク テストのリリースは、マルチターン対話およびマルチ言語処理における大規模言語モデルの研究に重要な参考資料を提供するとともに、将来のモデル改善への道を示します。将来的には、複雑な複数ラウンドの複数言語タスクの課題にうまく対処するために、より強力な LLM が登場すると予想されます。