Zhiyuan Research Institute の Emu3 チームは、革新的なマルチモーダル モデル Emu3 をリリースしました。これは、従来のマルチモーダル モデル アーキテクチャを覆し、次のトークンの予測のみに基づいてトレーニングし、生成タスクと認識タスクで SOTA パフォーマンスを達成します。 Emu3 チームは、画像、テキスト、ビデオを個別の空間に巧みにトークン化し、混合マルチモーダル シーケンスで単一の Transformer モデルをトレーニングし、拡散や組み合わせアーキテクチャに依存せずにマルチモーダル タスクの統合を実現します。新たな突破口。
Zhiyuan Research Institute の Emu3 チームは、新しいマルチモーダル モデル Emu3 をリリースしました。このモデルは、次のトークンの予測にのみ基づいてトレーニングされ、従来の拡散モデルと組み合わせモデルのアーキテクチャを覆し、生成タスクと認識状態の両方で結果を達成します。最先端のパフォーマンス。
次のトークンの予測は、汎用人工知能 (AGI) への有望な手段と長い間考えられてきましたが、マルチモーダル タスクではあまりうまく機能しませんでした。現在、マルチモーダル分野は依然として拡散モデル (安定拡散など) と組み合わせモデル (CLIP と LLM の組み合わせなど) によって支配されています。 Emu3 チームは、画像、テキスト、ビデオを個別の空間にトークン化し、混合マルチモーダル シーケンスで単一の Transformer モデルをゼロからトレーニングすることで、拡散や組み合わせアーキテクチャに依存せずにマルチモーダル タスクを統合します。
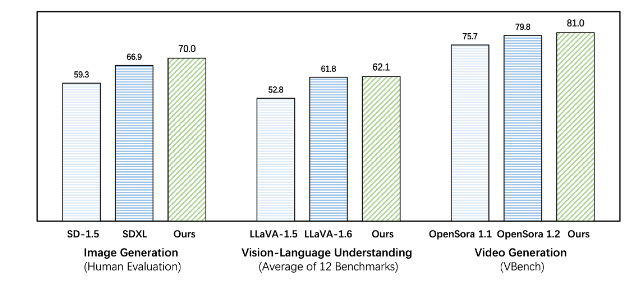
Emu3 は、生成タスクと認識タスクの両方で既存のタスク固有モデルを上回り、SDXL や LLaVA-1.6 などの主力モデルをも上回ります。 Emu3 は、ビデオ シーケンス内の次のトークンを予測することで、高忠実度のビデオを生成することもできます。 ビデオ拡散モデルを使用してノイズからビデオを生成する Sora とは異なり、Emu3 はビデオ シーケンス内の次のトークンを予測することによって因果関係のある方法でビデオを生成します。このモデルは、現実世界の環境、人々、動物の特定の側面をシミュレートし、ビデオのコンテキストを考慮して次に何が起こるかを予測できます。
Emu3 は、複雑なマルチモーダル モデルの設計を簡素化し、トークンに焦点を当て、トレーニングと推論中に大きなスケーリングの可能性を解き放ちます。 研究結果は、次のトークンの予測が言語を超えた一般的なマルチモーダル インテリジェンスを構築する効果的な方法であることを示しています。この分野のさらなる研究を支援するために、Emu3 チームは、これまで一般公開されていなかった、ビデオや画像を個別のトークンに変換できる強力なビジュアル トークナイザーなどの主要なテクノロジーとモデルをオープンソース化しました。
Emu3 の成功は、マルチモーダル モデルの将来の開発の方向性を示し、AGI の実現に新たな希望をもたらします。
プロジェクトアドレス: https://github.com/baaivision/Emu3
Downcodes エディターの要約: Emu3 モデルの登場は、マルチモーダル分野における新たなマイルストーンを示しています。そのシンプルなアーキテクチャと強力なパフォーマンスは、将来の AGI 研究に新しいアイデアと方向性を提供します。オープンソース戦略は学界と産業界の共同開発も促進しており、今後のさらなるブレークスルーに期待する価値があります。