大規模言語モデル (LLM) の急速な開発には目を見張るものがありますが、モデル規模の拡大を追求するだけでは真の AI インテリジェンスを実現するには十分ではありません。 Downcodes の編集者は、モデルに自己進化能力を与え、推論段階で学習と改善を継続できるようにすることが、AI の将来の開発にとって重要であると考えています。この記事では、AI の自己進化の重要な要素である長期記憶 (LTM) と、LTM を通じて AI の継続的な進歩を達成する方法について説明します。
GPT シリーズなどの大規模言語モデル (LLM) は、膨大なデータセットを使用して言語の理解、推論、計画において驚くべき能力を実証し、さまざまな困難なタスクにおいて人間と同等のレベルに達しました。ほとんどの研究は、より強力な基本モデルを開発することを目的として、大規模なデータセットでモデルをトレーニングすることでこれらのモデルをさらに強化することに焦点を当てています。
ただし、より強力な基本モデルをトレーニングすることは重要ですが、研究者は、モデルに推論段階で進化し続ける能力、つまり AI の自己進化を与えることも AI の開発にとって重要であると考えています。大規模なデータを使用してモデルをトレーニングする場合と比較して、自己進化には限られたデータまたはインタラクションのみが必要な場合があります。
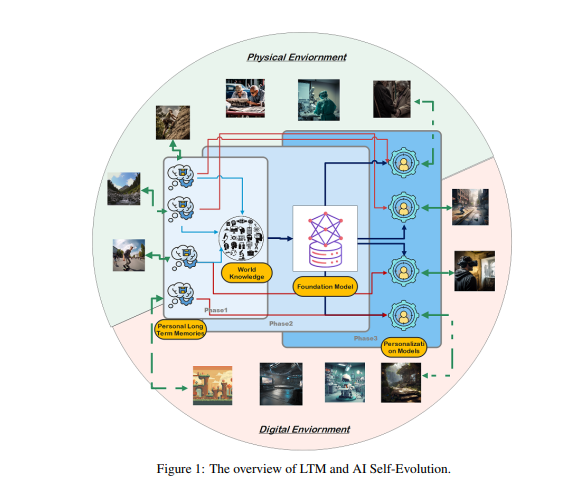
研究者らは、人間の大脳皮質の柱状構造にヒントを得て、AI モデルが環境との反復的な相互作用を通じて創発的認知能力を開発し、内部表現モデルを構築できるという仮説を立てました。
この目標を達成するために、研究者らは、処理された実世界のインタラクション データを保存および管理するための長期記憶 (LTM) をモデルに持たせる必要があると提案しました。 LTM は、ロングテールの個人データを統計モデルで表現できるだけでなく、さまざまな環境やエージェントにわたる多様なエクスペリエンスをサポートすることで自己進化を促進します。
AIの自己進化を実現するにはLTMが鍵となる。 人間が個人的な経験や環境とのインタラクションを通じて継続的に学習し改善するのと同様に、AI モデルの自己進化もインタラクション中に蓄積された LTM データに依存しています。人間の進化とは異なり、LTM 主導のモデルの進化は現実世界のインタラクションに限定されません。モデルは人間と同じように物理環境と対話し、直接フィードバックを受け取ることができ、そのフィードバックは処理されてその能力を強化します。これは、身体化 AI の重要な研究分野でもあります。
一方で、モデルは仮想環境で対話し、LTM データを蓄積することもできます。これは現実世界の対話よりも低コストで効率的であり、それによって機能をより効果的に強化できます。
LTM を構築するには、生データを調整して構造化する必要があります。 生データとは、外部環境との対話を通じて、またはトレーニング プロセス中にモデルが受信したすべての未処理データのコレクションを指します。 これらのデータにはさまざまな観察や記録が含まれており、貴重なパターンや大量の冗長または無関係な情報が含まれる場合があります。
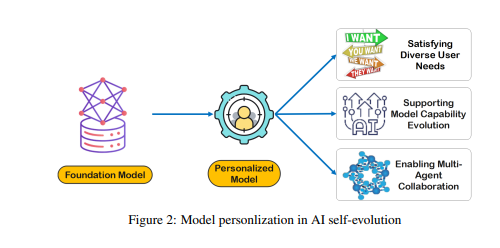
生データはモデルの記憶と認知の基礎を形成しますが、パーソナライゼーションや効率的なタスクの実行に効果的に使用するには、さらなる処理が必要です。 LTM はこれらの生データを改良して構造化し、モデルで使用できるようにします。このプロセスにより、パーソナライズされた応答と推奨事項を提供するモデルの機能が強化されます。
LTM の構築は、データの希薄性やユーザーの多様性などの課題に直面しています。 継続的に更新される LTM システムでは、データの希薄性が一般的な問題であり、特にインタラクション履歴が限られているユーザーやアクティビティが分散しているユーザーにとっては、モデルのトレーニングが困難になります。 さらに、ユーザーの多様性により複雑さが増し、モデルが個々のパターンに適応することと、異なるユーザー グループ全体で効果的に一般化することの両方が必要になります。
研究者らは、LTM に基づいて AI の自己進化を実装する、Omne と呼ばれるマルチエージェント コラボレーション フレームワークを開発しました。 このフレームワークでは、各エージェントは独立したシステム構造を持ち、完全な環境モデルを自律的に学習および保存して、環境についての独立した理解を構築できます。 このLTMに基づく共同開発により、AIシステムは個人の行動の変化にリアルタイムで適応し、タスクの計画と実行を最適化し、パーソナライズされた効率的なAIの自己進化をさらに促進することができます。
Omne フレームワークは GAIA ベンチマーク テストで 1 位を獲得し、AI の自己進化と現実世界の問題の解決に LTM を活用する大きな可能性を証明しました。 研究者らは、LTM 研究を進めることが、特に自己進化の観点から、AI テクノロジーの継続的な開発と実用化に不可欠であると信じています。
全体として、長期記憶は AI の自己進化の鍵であり、AI モデルが人間と同じように経験から学習し、改善できるようになります。 LTM を構築して活用するには、データの希薄性やユーザーの多様性などの課題を克服する必要があります。 Omne フレームワークは、LTM ベースの AI 自己進化のための実現可能なソリューションを提供し、GAIA ベンチマーク テストでの成功は、この分野における大きな可能性を示しています。
論文: https://arxiv.org/pdf/2410.15665
長期記憶 (LTM) の研究により、AI の自己進化はもはや遠い夢ではありません。 将来的には、LTMベースのAIモデルがより幅広い分野でより強力な能力を発揮し、人類社会に大きな利益をもたらすことが期待されます。 さらなる革新的な結果を期待しています!