近年、人工知能はさまざまな分野で大きな進歩を遂げていますが、その数的推論能力が常にネックとなっていました。 現在、FrontierMath と呼ばれる新しいベンチマークの出現により、AI の数学的能力を評価するための新しい基準が提供され、AI の数学的推論能力が前例のない限界に達し、既存の AI モデルに深刻な課題をもたらしています。 Downcodes の編集者は、FrontierMath を深く理解し、それが AI の数学的能力についての私たちの理解をどのように覆すのかを説明します。
人工知能の広大な宇宙において、かつては数学が機械知能の最後の砦とみなされていました。今日、AI の数学的推論能力を前例のない限界まで押し上げる、FrontierMath と呼ばれる新しいベンチマーク テストが登場しました。
エポックAIは、数学界のトップブレーン60名以上と手を組み、数学オリンピックともいえるこのAIチャレンジフィールドを共同で創設しました。これは技術的なテストであるだけでなく、人工知能の数学的知恵を試す究極のテストでもあります。
一般人の想像を超える数百の数学パズルを作り上げた世界トップの数学者でいっぱいの研究室を想像してみてください。これらの問題は、数論、実数解析、代数幾何学、圏論などの最先端の数学分野にまたがっており、驚くほど複雑です。国際数学オリンピックの金メダルを獲得した数学の天才でも、問題を解くには数時間、場合によっては数日を要します。
衝撃的なことに、現在の最先端の AI モデルは、このベンチマークで期待外れのパフォーマンスを示しました。問題の 2% 以上を解決できるモデルはありませんでした。この結果は警鐘のようなもので、AIの顔を平手打ちした。
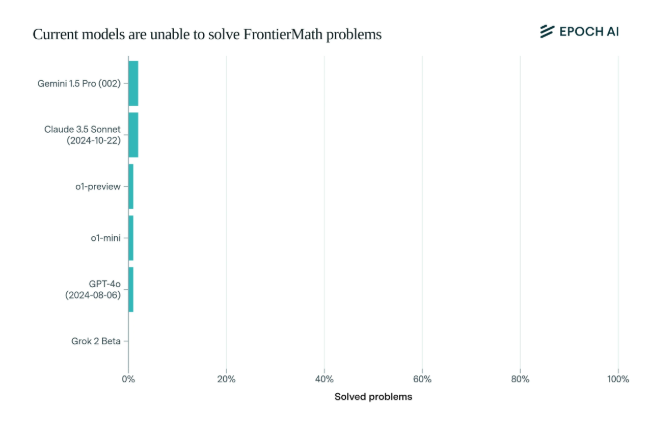
FrontierMath のユニークな点は、その厳格な評価メカニズムです。 MATH や GSM8K などの従来の数学テスト ベンチマークは AI によって最大限に活用されており、この新しいベンチマークは、新しい未公開の問題と自動検証システムを使用して、データ汚染を効果的に回避し、AI の数学的推論能力を真にテストします。
このテストでは、注目を集めていたOpenAI、Anthropic、Google DeepMindといったAIトップ企業のフラッグシップモデルが一斉に逆転した。これは深い技術哲学を反映しています。コンピューターにとって、一見複雑な数学的問題は簡単かもしれませんが、人間が単純だと感じるタスクは AI を無力にする可能性があります。
アンドレイ・カルパシー氏が述べたように、これはモラベックのパラドックスを裏付けるものです。人間と機械の間の知的タスクの難しさは、多くの場合直感に反します。このベンチマーク テストは、AI の機能を厳密に検証するだけでなく、AI をより高次元に進化させる触媒でもあります。
数学コミュニティや AI 研究者にとって、FrontierMath は未征服のエベレストのようなものです。知識とスキルをテストするだけでなく、洞察力と創造的思考もテストします。将来、この知性の頂点を率先して登ることができる人は、人工知能開発の歴史に記録されるでしょう。
FrontierMath ベンチマーク テストの登場は、既存の AI 技術レベルの厳しいテストであるだけでなく、AI が数学的推論の分野でまだ長い道のりを歩んでいることを示しています。また、研究者は既存のテクノロジーのボトルネックを突破するために研究と革新を続けています。