今日、人間とコンピューターの対話がますます頻繁になっているため、スムーズで自然な会話エクスペリエンスは依然として課題となっています。 Downcodes の編集者が今日、画期的なテクノロジーである Moshi を紹介します。これは、Kyutai Labs が開発した全二重音声対話システムです。より自然でスムーズな人間と機械の会話を作成し、友人と話すのと同じくらい簡単に機械とのコミュニケーションを実現することに尽力しています。 Moshi の核となるイノベーションは、その独自の音声合成生成方法と、複数のオーディオ ストリームを同時に処理できる高度なテクノロジーにあります。Moshi の多くのハイライトを詳しく見てみましょう。
このデジタル時代では、機械との会話が日常生活の一部になっています。ただし、これらの会話には自然さや流れが欠けていることが多く、人間味が少し欠けているように感じられます。しかし、それは変わろうとしているかもしれない。 Kutai Labs が開発した全二重音声対話システム Moshi は、より自然でスムーズな人間とコンピュータの対話の新時代をもたらします。
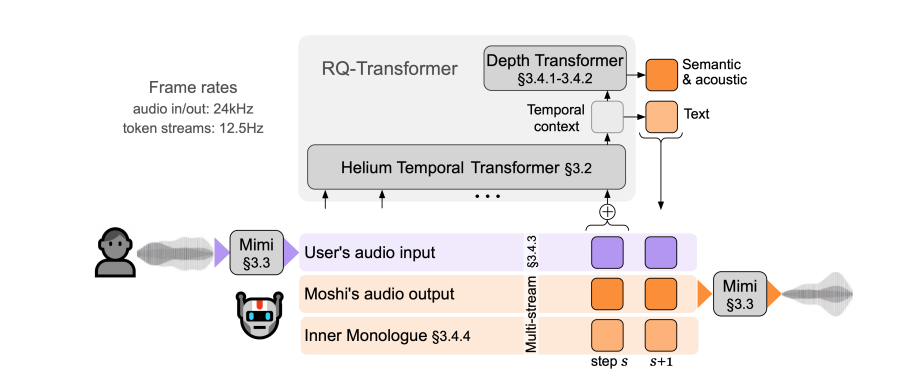
Moshi は、音声とテキストに基づいた対話モデルであり、その中心的な革新は、対話を音声変換生成プロセスとして扱うことにあります。この方法は、遅延、情報損失、交代の制限など、従来の音声対話システムに存在する多くの問題を巧みに解決します。 Moshi は、私たち人間と同じように、聞くことと話すことを同時に行うことができ、会話の重複、中断、口出しを簡単に処理できるという点でユニークです。
Moshi の強力な機能は 3 つのコア テクノロジーから生まれています。 1 つ目は Moshi の頭脳である Helium テキスト言語モデルで、70 億のパラメータを持ち、膨大な英語データを学習することで強力な言語理解と生成機能を備えています。次は Mimi Neural Audio Codec です。これは Moshi の口と耳として機能し、音声信号とモデルが理解できる個別単位の間で変換を行います。最後に、マルチストリーム オーディオ言語モデルは Moshi の革新的なもので、複数のオーディオ ストリームを同時に処理し、複数の話者の音声を同時に理解できるようにします。
Moshi には独自のインナーモノローグ機能もあります。音声を生成する前に、音声トークンと同期した時間調整されたテキスト トークンを事前予測します。これにより、生成された音声の言語品質が向上するだけでなく、ストリーミング音声認識およびテキスト読み上げサービスも提供され、会話機能がさらに強化されます。
さまざまなパフォーマンステストで、Moshi は優れたパフォーマンスを示しました。テキスト理解、音声明瞭度、音声品質、音声による質疑応答のいずれにおいても、Moshi は既存の音声テキスト モデルの中で最高のレベルに達しています。これは、人間とコンピューターの真に自然でスムーズな対話に一歩近づいたことを意味します。
しかし、AI技術の発展に伴い、セキュリティの問題がますます顕著になってきています。 Moshi の開発チームが最初からこれを考慮していたことは注目に値します。システムのセキュリティを確保するために、有害なコンテンツの生成の回避、ユーザーのプライバシーの保護、健全な一貫性の確保など、いくつかの対策を講じています。 Moshi は、ユーザーの声を模倣せず、自身の声の一貫性を維持しながら、不適切な質問を特定して回答を拒否することができるため、ユーザーにさらなるセキュリティを提供します。
Moshi の出現はテクノロジーの画期的な進歩であるだけでなく、人間とコンピューターの相互作用の方法における大きな革新の到来を告げるものでもあります。それは私たちに将来の対話システムの無限の可能性を示し、人間と機械の間の自然でスムーズかつ人間的な対話の明るい展望を私たちに見せてくれます。この技術が開発と改良を続ければ、近い将来、真にバリアフリーで高品質な機械との通信が実現され、SF映画のシーンが現実に再現されるようになるかもしれません。
モデルアドレス:https://huggingface.co/kyutai/mosiko-pytorch-bf16
論文アドレス:https://kyutai.org/Moshi.pdf
Moshi の登場は、将来の人間とコンピューターの相互作用への道を示しており、そのスムーズで自然な会話体験は刺激的です。テクノロジーの継続的な進歩により、人間と機械の間のコミュニケーションはますます便利で自然になり、最終的には真のバリアフリーコミュニケーションが実現すると考えられています。待って見てみましょう!