Apple の AI 研究チームは、新世代のマルチモーダル大規模言語モデル ファミリー MM1.5 をリリースしました。MM1.5 は、テキストや画像などの複数のデータ タイプを統合でき、視覚的な質問応答、画像生成、複数のタスクで強力なパフォーマンスを実証しました。モーダルデータ解釈能力。 MM1.5 は、革新的なデータ中心のアプローチを通じて、テキストの多い画像と詳細な視覚タスクを処理する際の以前のマルチモーダル モデルの困難を克服し、高解像度の OCR データと合成画像の説明を使用してモデルのパフォーマンスを大幅に向上させます。理解。 Downcodes のエディターでは、MM1.5 の革新性と複数のベンチマーク テストにおける優れたパフォーマンスを深く理解できます。
最近、Apple の AI 研究チームは、新世代のマルチモーダル大規模言語モデル (MLLM) ファミリ - MM1.5 を発表しました。この一連のモデルは、テキストや画像などの複数のデータ タイプを組み合わせることができ、複雑なタスクを理解する AI の新しい能力を示しています。視覚的な質問応答、画像生成、マルチモーダル データ解釈などのタスクはすべて、これらのモデルの助けを借りてより適切に解決できます。
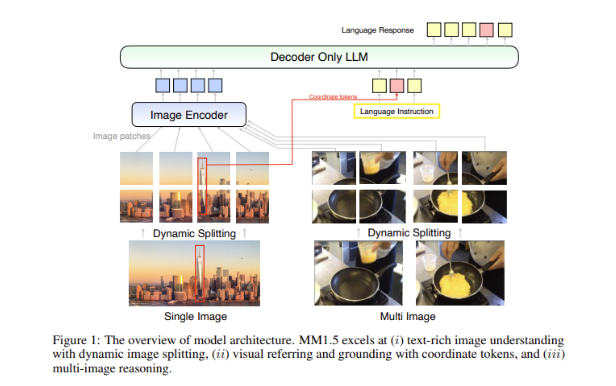
マルチモーダル モデルにおける大きな課題は、異なるデータ タイプ間で効果的な相互作用を実現する方法です。過去のモデルは、テキストの多い画像やきめ細かい視覚タスクに苦労することがよくありました。そのため、Apple の研究チームは、高解像度の OCR データと合成画像の説明を使用して、モデルの理解機能を強化する革新的なデータ中心の手法を MM1.5 モデルに導入しました。
この方法により、MM1.5 は視覚的な理解と位置決めタスクにおいて以前のモデルを上回ることができるだけでなく、モデルの 2 つの特殊なバージョンである MM1.5-Video と MM1.5-UI も起動され、それぞれビデオの理解と位置決めに使用されます。モバイルインターフェース分析。
MM1.5 モデルのトレーニングは 3 つの主要な段階に分かれています。
最初の段階は大規模な事前トレーニングで、20 億の画像とテキスト データのペア、6 億のインターリーブされた画像とテキストのドキュメント、および 2 兆のテキストのみのトークンを使用します。
第 2 段階では、4,500 万の高品質 OCR データと 700 万の合成記述の継続的な事前トレーニングを通じて、テキスト強化画像タスクのパフォーマンスをさらに向上させます。
最後に、監視付き微調整段階では、モデルは、詳細な視覚的参照と複数画像の推論を向上させるために、慎重に選択された単一画像、複数画像、およびテキストのみのデータを使用して最適化されます。
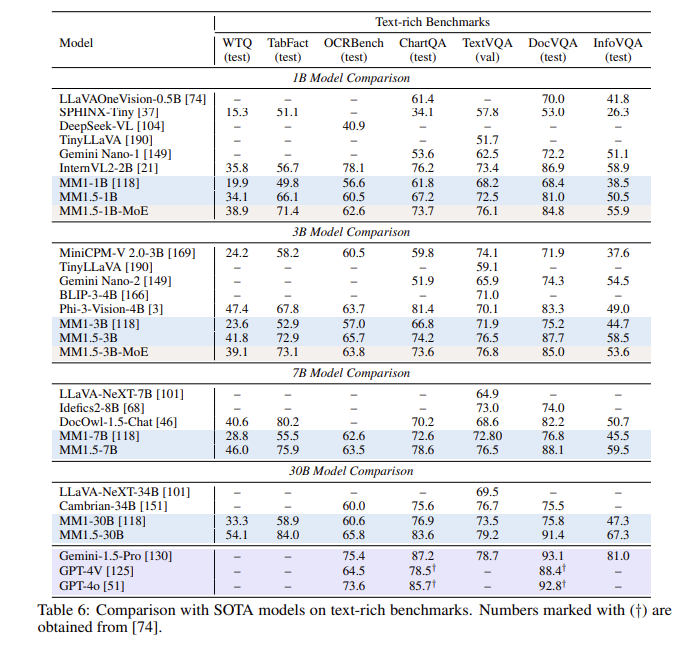
一連の評価の後、MM1.5 モデルは複数のベンチマーク テストで良好なパフォーマンスを示し、特にテキストが豊富な画像の理解を扱う場合に、前モデルと比べて 1.4 ポイント向上しました。さらに、ビデオ理解用に特別に設計された MM1.5-Video でさえ、その強力なマルチモーダル機能により、関連タスクにおいてトップレベルに達しています。
MM1.5 モデル ファミリは、マルチモーダル大規模言語モデルの新しいベンチマークを設定するだけでなく、一般的な画像テキストの理解からビデオやユーザー インターフェイスの分析まで、さまざまなアプリケーションでその可能性を実証し、すべて優れたパフォーマンスを発揮します。
ハイライト:
**モデルのバリエーション**: 10 億から 300 億のパラメータを持つ高密度モデルと MoE モデルが含まれており、スケーラビリティと柔軟な展開を保証します。
? **トレーニング データ**: 20 億の画像とテキストのペア、6 億のインターリーブされた画像とテキストのドキュメント、および 2 兆のテキストのみのトークンを利用します。
**パフォーマンスの向上**: 文字が多い画像の理解に重点を置いたベンチマーク テストで、前モデルと比較して 1.4 ポイントの向上を達成しました。
全体として、Apple の MM1.5 モデル ファミリーは、マルチモーダル大規模言語モデルの分野で大きな進歩を遂げており、その革新的な手法と優れたパフォーマンスは、将来の AI 開発に新たな方向性をもたらします。 MM1.5 がより多くのアプリケーション シナリオでその可能性を示すことを楽しみにしています。