情報爆発の時代においては、画像内の文字情報を効率的に処理することが重要です。 Downcodes の編集者は本日、革新的な OCR モデル、GOT (一般光学文字認識理論) を紹介します。これは、OCR テクノロジーが 2.0 時代に突入することを示します。 GOT モデルは、従来の OCR モデルと大規模言語モデルの利点を組み合わせ、その強力なパフォーマンスと多用途性によりテキスト認識の分野に新たなブレークスルーをもたらします。英語や中国語の文書や情景テキストの認識だけでなく、数式や化学式、音楽記号、図表などの複雑な情報も扱うことができ、OCRの分野では「オールラウンドプレイヤー」と言えます。
デジタル時代では、画像内のテキスト コンテンツを編集可能なテキストに迅速に変換することは一般的かつ重要な要件です。現在、GOT (General Optical Character Recognition Theory) と呼ばれる新しい光学式文字認識 (OCR) モデルの出現により、OCR テクノロジは 2.0 時代に突入しました。この革新的なモデルは、従来の OCR システムと大規模言語モデルの利点を組み合わせて、より効率的でインテリジェントなテキスト認識ツールを作成します。
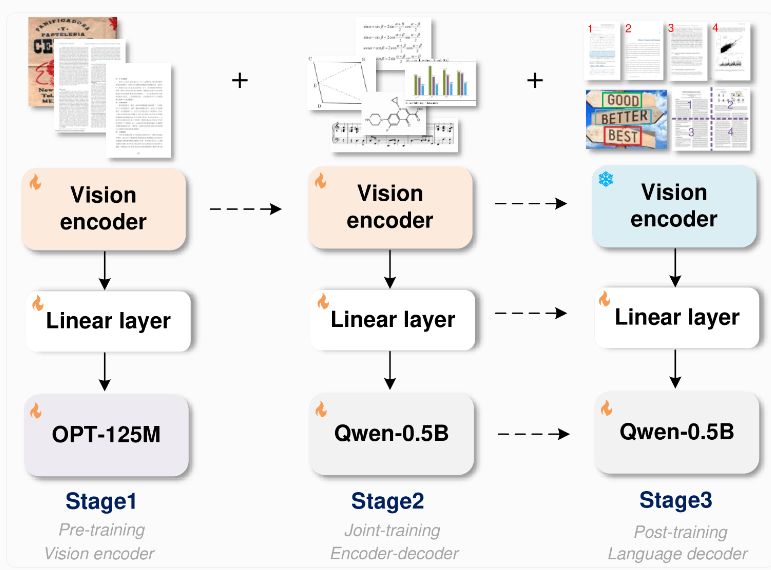
GOT モデルは革新的なエンドツーエンド アーキテクチャを採用しており、リソースを節約するだけでなく、認識機能をテキスト認識を超えて大幅に拡張します。このモデルは、約 8,000 万のパラメータを持つ画像エンコーダと、約 500 万のパラメータを持つデコーダで構成されます。画像エンコーダは、最大 1024x1024 ピクセルの画像をデータ単位に圧縮でき、デコーダはこのデータを最大 8000 文字の長さのテキストに変換します。
GOT の強みは、英語や中国語の文書や場面テキストを認識して変換できるだけでなく、数式や化学式、音楽記号、単純な幾何学図形、さまざまなチャートも処理できる多機能さにあります。これにより、GOT は真のオールラウンダーになります。
このモデルをトレーニングするために、研究チームはまずテキスト認識タスクに焦点を当て、次にアリババの Qwen-0.5B をデコーダとして使用し、さまざまな合成データを使用して微調整しました。彼らは、LaTeX、Mathpix-markdown-it、Matplotlib などのプロフェッショナルなレンダリング ツールを使用して、モデル トレーニング用に何百万もの画像とテキストのペアを生成しました。

OCR2.0 テクノロジのもう 1 つのハイライトは、書式設定されたテキスト、タイトル、さらには複数ページの画像を抽出し、構造化されたデジタル形式に変換する機能です。これにより、科学、音楽、データ分析などの分野における自動処理と分析の新たな可能性が開かれます。
さまざまな OCR タスクのテストにおいて、GOT は優れたパフォーマンスを実証し、ドキュメントおよびシーンのテキスト認識において業界をリードする結果を達成し、チャート認識においては多くのプロフェッショナル モデルや大規模言語モデルをも上回りました。複雑な化学構造式であっても、楽譜やデータの視覚化であっても、OCR2.0 はそれらを正確にキャプチャし、機械可読形式に変換できます。
より多くのユーザーがこのテクノロジーを体験して利用できるようにするために、研究チームは、Hugging Face プラットフォーム上で無料のデモとコードをリリースしました。 OCR2.0 の登場は、間違いなく情報処理の分野に革命をもたらしました。効率が向上するだけでなく、柔軟性も向上し、画像内のテキスト情報をより簡単に処理できるようになります。
GOT モデルの登場は間違いなく OCR テクノロジーに新たな活力を吹き込み、その効率的で正確かつ多用途な機能はあらゆる分野で広く使用され、人々の仕事と生活にさらなる利便性をもたらします。今後もGOTモデルをさらに改良し、さらなる驚きをお届けできることを楽しみにしています。