Apple は、マルチモーダル人工知能モデル MM1 ~ MM1.5 のメジャー アップグレードをリリースしました。このアップグレードは単純なバージョンの反復ではなく、モデルの機能を全面的に改善し、画像の理解、テキスト認識、および視覚的なコマンドの実行におけるパフォーマンスを大幅に向上させます。 Downcodes の編集者が、MM1.5 の改良点とマルチモーダル人工知能分野におけるその重要性について詳しく説明します。
Apple は最近、マルチモーダル人工知能モデル MM1 のメジャー アップデートを開始し、バージョン MM1.5 にアップグレードしました。今回のバージョンアップは単なるバージョン番号の変更ではなく、総合的な性能向上を図り、さまざまな分野でより強力なパフォーマンスを発揮できるようになりました。
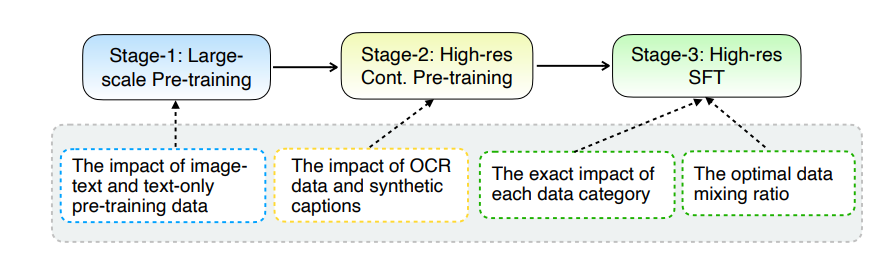
MM1.5 のアップグレードの核心は、その革新的なデータ処理方法にあります。このモデルはデータ中心のトレーニング アプローチを採用しており、トレーニング データ セットは慎重に選別され、最適化されています。具体的には、MM1.5 は、高解像度の OCR データと合成画像の説明に加え、データの組み合わせを微調整するために最適化された視覚的な指示を使用します。これらのデータの導入により、テキスト認識、画像理解、および視覚的指示の実行におけるモデルのパフォーマンスが大幅に向上しました。

モデル サイズの点で、MM1.5 は、集中型および専門家混合 (MoE) バリアントを含む、10 億から 300 億のパラメーターにわたる複数のバージョンをカバーしています。より小規模な 10 億および 30 億のパラメーター モデルでも、慎重に設計されたデータとトレーニング戦略を使用して優れたパフォーマンス レベルを達成できることは注目に値します。
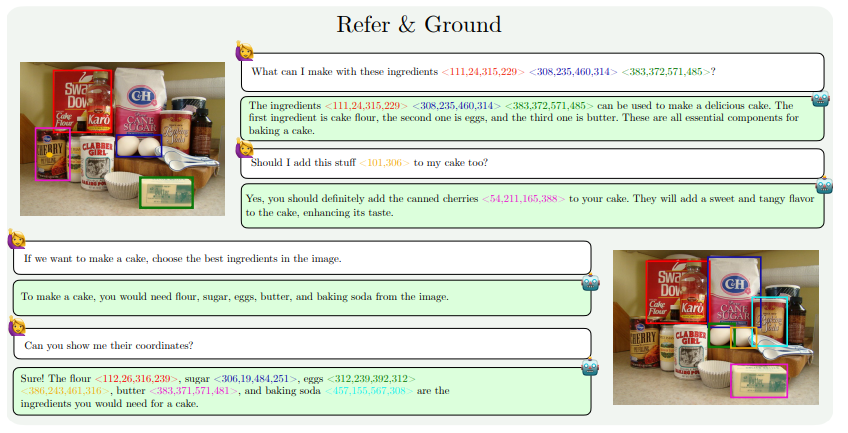
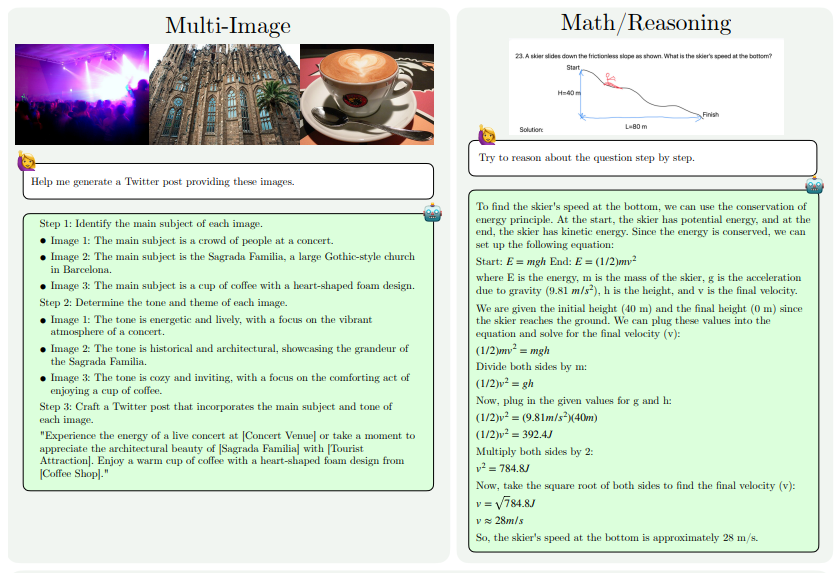
MM1.5 の機能向上は主に、テキスト中心の画像の理解、視覚的な参照と位置決め、複数の画像の推論、ビデオの理解、およびモバイル UI の理解の側面に反映されています。これらの機能により、MM1.5 は、コンサート写真からの演奏者や楽器の特定、チャート データの理解と関連する質問への回答、複雑なシーンでの特定のオブジェクトの位置の特定など、より幅広いシナリオに適用できます。
MM1.5 のパフォーマンスを評価するために、研究者らはそれを他の高度なマルチモーダル モデルと比較しました。結果は、MM1.5-1B が 10 億パラメーターのスケールのモデルで良好なパフォーマンスを示し、同じレベルの他のモデルよりも大幅に優れていることを示しています。 MM1.5-3B は MiniCPM-V2.0 よりも優れており、InternVL2 および Phi-3-Vision と同等です。さらに、この研究では、高密度モデルであっても MoE モデルであっても、規模が大きくなるにつれてパフォーマンスが大幅に向上することもわかりました。
MM1.5の成功は、人工知能分野におけるAppleの研究開発力を反映しているだけでなく、マルチモーダルモデルの将来の開発への道を示しています。データ処理方法とモデル アーキテクチャを最適化することで、小規模なモデルでも優れたパフォーマンスを実現できます。これは、リソースに制約のあるデバイスに高性能 AI モデルを展開する場合に非常に重要です。
論文アドレス: https://arxiv.org/pdf/2409.20566
全体として、MM1.5 のリリースは、マルチモーダル人工知能テクノロジーの大幅な進歩を示しています。データ処理とモデル アーキテクチャにおける革新は、将来の AI モデルの開発に新しいアイデアと方向性を提供します。私たちは、Apple が人工知能の分野でさらなる画期的な成果をもたらし続けることを期待しています。