Downcodes のエディターは、AI 分野における不穏な現象であるモデルの崩壊を理解するよう導きます。 AI モデルが、自分の作った料理を食べ始めると、どんどん中毒になってしまい、最終的には「まずい」ものになってしまうと想像してください。モデルが崩壊するときです。これは、AI モデルが生成するデータに過度に依存し、モデルの品質が低下したり、完全に失敗したりする場合に発生します。この記事では、モデルの崩壊の原因、影響、および回避方法について詳しく説明します。
最近、AI界隈で奇妙な現象が起こっている。あるフードブロガーが自分の作った料理を突然食べ始め、食べれば食べるほど中毒になって、どんどん料理が不味くなっていくというものだ。これを専門用語でモデル崩壊と言うのは非常に恐ろしいことです。
モデル崩壊とは簡単に言うと、AI モデルがトレーニング プロセス中に大量の自己生成データを使用すると、悪循環に陥り、モデル生成の品質がますます低下し、最終的には悪化します。失敗。
これは閉じた生態系のようなもので、AI モデルはこのシステム内で唯一の生き物であり、AI モデルが生成する食料はデータです。当初はまだ天然成分 (実際のデータ) を見つけることができましたが、時間が経つにつれて、生成した「人工」成分 (合成データ) にますます依存するようになりました。問題は、これらの「人工」成分が栄養不足であり、モデル自体にいくつかの欠陥があることです。食べすぎるとAIモデルの「肉体」が崩壊し、生成されるものはどんどんとんでもないものになっていきます。
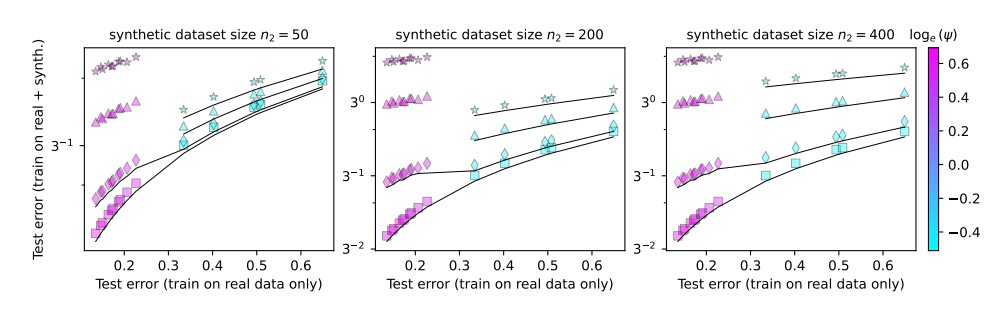
この論文では、モデル崩壊の現象を研究し、次の 2 つの重要な質問に答えようとします。
モデルの崩壊は避けられないのでしょうか? 実データと合成データを混合することで問題を解決できますか?
モデルが大きくなるとクラッシュしやすくなりますか?
これらの問題を研究するために、論文の著者らは一連の実験を計画し、ランダム投影モデルを使用してニューラル ネットワークのトレーニング プロセスをシミュレートしました。彼らは、合成データのごく一部 (たとえば 1%) を使用しただけでもモデルが崩壊する可能性があることを発見しました。さらに悪いことに、モデルのサイズが大きくなるにつれて、モデルの崩壊現象がより深刻になります。
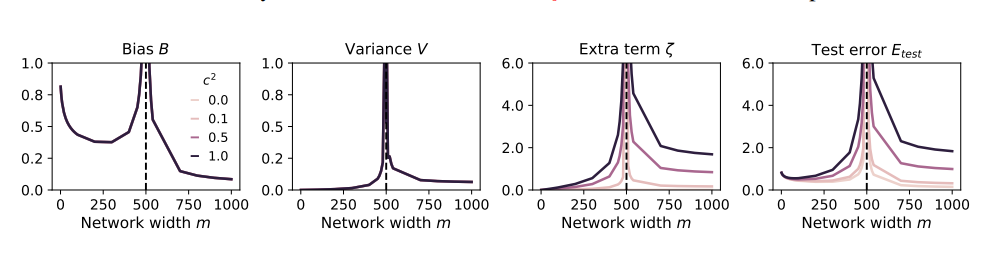
これは、注目を集めるためにあらゆる種類の奇妙な食材を試し始めたものの、結局お腹を壊してしまったグルメブロガーのようなものです。損失を取り戻すために、彼は食事量を増やし、より多くの奇妙なものを食べることしかできませんでしたが、その結果、胃の調子が悪くなり、最終的には食べることと放送の世界を辞めなければなりませんでした。
では、モデルの崩壊を避けるにはどうすればよいでしょうか?
この論文の著者は次のような提案をしました。
リアルデータの使用を優先する: リアルデータは自然食品のようなもので、栄養素が豊富で、AI モデルの健全な成長の鍵となります。
合成データは慎重に使用してください。合成データは人工食品のようなものですが、一部の栄養素を補うことができますが、あまり頼りすぎないようにしてください。そうしないと逆効果になります。
モデルのサイズを制御する: モデルが大きいほど、食欲が増し、胃が悪くなりやすくなります。合成データを使用する場合は、オーバーフィードを避けるためにモデルのサイズを制御します。
モデルの崩壊は、AI の開発プロセスで遭遇する新たな課題であり、モデルの規模と効率を追求する一方で、データの品質とモデルの健全性にも注意を払う必要があることを思い出させます。この方法によってのみ、AI モデルは健全に発展し続け、人間社会により大きな価値を生み出すことができます。
論文: https://arxiv.org/pdf/2410.04840
全体として、モデルの崩壊は AI の開発において注目に値する問題であり、「AI」現象を回避するには、合成データを慎重に扱い、実際のデータの品質に注意を払い、モデルの規模を制御する必要があります。食べ過ぎです。」この分析が、誰もがモデル崩壊をより深く理解し、AI の健全な発展に貢献できることを願っています。