Downcodes の編集者がビッグニュースをお届けします!人工知能の分野に新しいメンバーが加わりました - Zyphra が小型言語モデル Zamba2-7B を正式にリリースしました。この 70 億のパラメータ モデルは、特に効率と適応性の点でパフォーマンスの画期的な進歩を達成し、印象的な利点を示しています。高性能コンピューティング環境に適しているだけでなく、さらに重要なことに、Zamba2-7B はコンシューマーグレードの GPU でも実行できるため、より多くのユーザーが高度な AI テクノロジーの魅力を簡単に体験できるようになります。この記事では、Zamba2-7B の革新性とそれが自然言語処理の分野に与える影響について詳しく説明します。
最近、Zyphra は、パラメータ数が 7B に達する、前例のないパフォーマンスを備えた小型言語モデルである Zamba2-7B を正式にリリースしました。
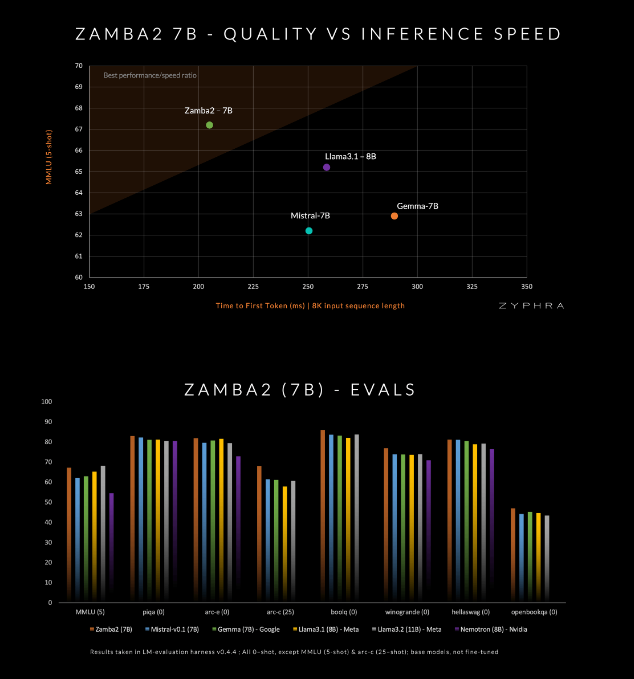
このモデルは、Mistral-7B、Google の Gemma-7B、Meta の Llama3-8B など、現在の競合他社を品質と速度で上回ると主張しています。
Zamba2-7B は、強力な言語処理機能を必要とするが、オンデバイス処理やコンシューマ グレードの GPU の使用などのハードウェア条件によって制限される環境のニーズを満たすように設計されています。 Zyphra は、品質を犠牲にすることなく効率を向上させることで、企業や個人開発者など、より幅広いユーザーが高度な AI の利便性を享受できるようにしたいと考えています。
Zamba2-7B は、モデルの効率と表現能力を向上させるために、アーキテクチャに多くの革新を加えました。前世代モデルの Zamba1 とは異なり、Zamba2-7B は 2 つの共有アテンション ブロックを使用し、情報フローとシーケンス間の依存関係をより適切に処理できます。
Mamba2 ブロックはアーキテクチャ全体の中核を形成しており、これによりモデルのパラメーター使用率が従来のコンバーター モデルよりも高くなります。さらに、Zyphra は共有 MLP ブロックで低ランク適応 (LoRA) 射影も使用します。これにより、モデルのコンパクトさを維持しながら各層の適応性がさらに向上します。これらの革新のおかげで、 Zamba2-7B の最初の応答時間は 25% 短縮され、1 秒あたりに処理されるトークンの数は 20% 増加しました。
Zamba2-7B の効率と適応性は、厳格なテストによって検証されています。このモデルは、高品質で厳密に選別されたオープン データである 3 兆のトークンを含む大規模なデータ セットで事前トレーニングされています。
さらに、Zyphra は、高品質のトークンをより効率的に処理するために学習率を迅速に下げる「アニーリング」事前トレーニング段階も導入しています。この戦略により、Zamba2-7B はベンチマークで優れたパフォーマンスを発揮し、推論速度と品質で競合他社を上回り、従来の高品質モデルに必要な大量のコンピューティング リソースを必要とせずに、自然言語の理解や生成などのタスクに適しています。
amba2-7B は、アクセシビリティに特別な注意を払いながら、高品質とパフォーマンスを維持する、小規模言語モデルの大きな進歩を表しています。革新的なアーキテクチャ設計と効率的なトレーニング技術により、Zyphra は使いやすいだけでなく、さまざまな自然言語処理のニーズを満たすことができるモデルの作成に成功しました。 Zamba2-7B のオープンソース リリースは、研究者、開発者、企業を招待してその可能性を探求し、より広範なコミュニティ内で高度な自然言語処理の開発を進めることが期待されています。
プロジェクト入口: https://www.zyphra.com/post/zamba2-7b
https://github.com/Zyphra/transformers_zamba2
Zamba2-7B のオープンソース リリースは、自然言語処理の分野に新たな活力をもたらし、開発者にさらなる可能性を提供しました。 Zamba2-7Bが将来的にさらに広く使用され、人工知能技術の継続的な進歩が促進されることを楽しみにしています。