Downcodes のエディターは、OCR テクノロジーの分野における大きな進歩について学びましょう。研究者らは最近、「OCR2.0」として知られる GOT (General OCR Theory) と呼ばれる OCR モデルを開発しました。これは、従来の OCR システムと大規模な言語モデルの利点を巧みに組み合わせたもので、テキスト認識機能の進歩において大きな成果を上げています。 。 GOT モデルは、洗練されたアーキテクチャ、強力な画像エンコーダおよびデコーダを備えており、複数の種類の視覚情報を処理できます。その応用の可能性は非常に広いです。
最近、研究者らは、GOT (General OCR Theory) と呼ばれる新しい汎用光学文字認識 (OCR) モデルを開発しました。彼らの論文では、「OCR2.0」の概念が最初に提案されました。この新しいモデルは、従来の OCR システムの利点と大規模な言語モデルの能力を組み合わせることが目的です。
GOTのアーキテクチャは非常に高度で、約8,000万パラメータの画像エンコーダと500万パラメータのデコーダを搭載しています。画像エンコーダーは 1024x1024 ピクセルの画像をトークンに圧縮し、デコーダーはこれらのトークンを最大 8000 文字のテキストに変換します。このように、OCR2.0 モデルは単純なテキスト以上のものを処理できます。
この新しいテクノロジーの優れた点は、英語や中国語のシーン テキストやドキュメント テキスト、数学や化学式、音楽記号、単純な幾何学図形、コンポーネントを含む図など、さまざまな種類の視覚情報を認識して変換できることにあります。このような機能は、科学、音楽、データ分析などの分野での自動処理に新たな可能性をもたらすことは間違いありません。
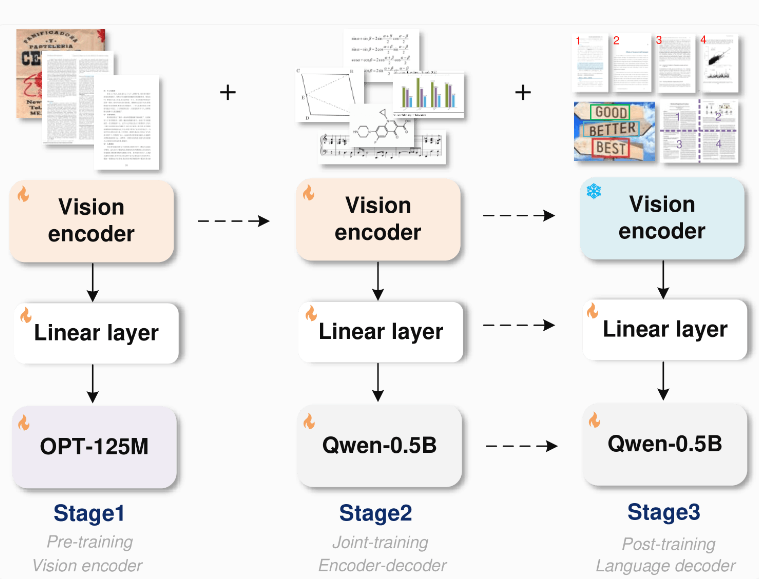
トレーニングプロセスを最適化するために、研究チームはまずエンコーダーをテキスト認識タスク専用にトレーニングし、次にアリババのQwen-0.5Bをデコーダーとして導入し、多様な合成データを使用してモデルを微調整しました。彼らは、LaTeX、Mathpix-markdown-it、TikZ、Verovio、Matplotlib、Pyecharts などのレンダリング ツールを使用して、何百万もの画像とテキストのペアのトレーニング データを生成しました。

GOTのモジュール設計により、モデル全体を再学習することなく、将来的に新しい機能を柔軟に拡張できるため、システムの更新効率が大幅に向上します。さらに、研究者らは、GOT はさまざまな OCR タスク、特に文書やシーンのテキスト認識で優れたパフォーマンスを発揮し、チャート認識では一部の特殊目的モデルや大規模言語モデルをも上回ると述べています。

研究チームが、他の人が使用してさらに開発できるように、Hugging Face に関する GOT の無料デモとコードをリリースしたことは言及する価値があります。この新しいモデルは間違いなく OCR 技術の開発を促進し、より幅広いアプリケーションの可能性を切り開きます。
デモの入り口: https://huggingface.co/spaces/stepfun-ai/GOT_official_online_demo
ハイライト:
? GOT (General OCR Theory) は、従来の OCR システムと OCR2.0 と呼ばれる大規模な言語モデルを組み合わせた新しい OCR モデルです。
?文字、数式、音楽記号、図表など様々な視覚情報を認識・変換することができ、幅広い分野に応用可能です。
? モジュラー設計と合成データ トレーニングにより、GOT は柔軟な拡張機能を備え、複数の OCR タスクで優れたパフォーマンスを実現します。
GOT モデルのオープンソース リリースは、間違いなく OCR テクノロジーの革新を加速し、よりスマートで効率的なテキスト認識ソリューションをあらゆる分野にもたらすでしょう。 GOTのさらなる可能性を今後の応用に期待します!