Downcodes の編集者は、イリノイ工科大学と他の大学の研究チームが新しい 3D シーンの大規模言語モデルである Robin3D を共同でリリースしたことを知りました。このモデルは、数百万の命令を含む大規模なデータセットでトレーニングされ、一般的に使用される 5 つの 3D マルチモーダル学習ベンチマークで最先端のパフォーマンスを達成しました。 Robin3D の革新性は、敵対的で多様な命令データを生成できるデータ エンジン RIG にあり、これによりモデルの識別、理解、汎化能力が向上し、既存の 3D 大規模言語モデルの不十分な汎化能力と過剰適合の問題が克服されます。また、リレーションシップ拡張プロジェクター (RAP) や ID フィーチャー バインディング (IFB) などのテクノロジーを統合して、シーンやオブジェクトに対するモデルの理解を強化します。
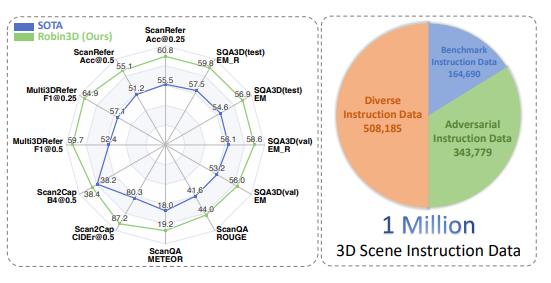
このモデルは、従うべき 100 万の命令を含む大規模なデータセットでトレーニングされ、一般的に使用される 5 つの 3D マルチモーダル学習ベンチマークで最先端のパフォーマンスを達成し、ユニバーサル 3D 構築における重要な一歩を示しました。インテリジェントエージェントの方向へ。
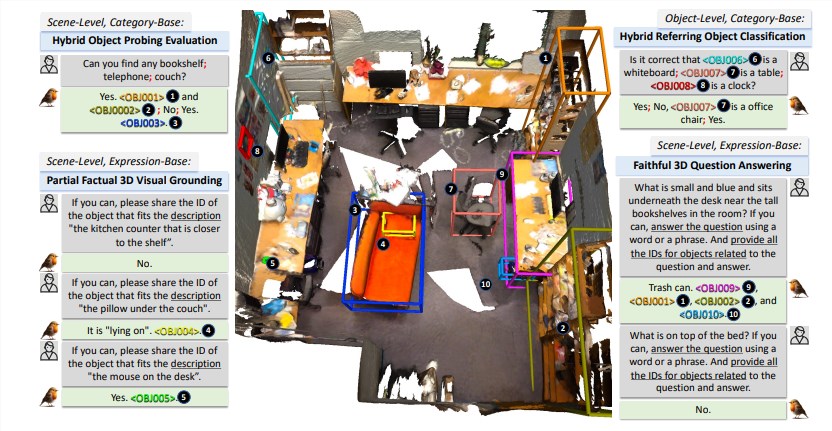
Robin3D の成功は、その革新的なデータ エンジン RIG (堅牢な命令生成) によるものです。 RIG エンジンは、敵対的コマンド コンプライアンス データと多様なコマンド コンプライアンス データという 2 つの主要なコマンド データ タイプを生成するように設計されています。
敵対的なフォロースルー データは、肯定的なサンプルと否定的なサンプルを混合することでモデルの識別的な理解を強化します。一方、多様なフォロースルー データには、モデルの汎化能力を強化するためのさまざまな指示スタイルが含まれています。
研究者らは、既存の 3D 大規模言語モデルは主にフロント 3D 視覚言語のペアリングとテンプレートベースのトレーニング命令に依存しているため、一般化機能が不十分であり、過剰適合のリスクがあると指摘しました。 Robin3D は、敵対的で多様な命令データを導入することで、これらの制限を効果的に克服します。
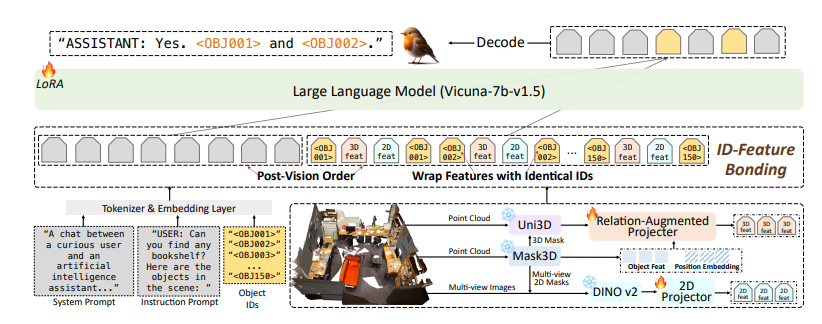
Robin3D モデルには、Relationship Augmented Projector (RAP) ID Feature Binding (IFB) の参照機能と位置決め機能も統合されています。 RAP モジュールは、豊富なシーンレベルのコンテキスト情報と位置情報を使用してオブジェクト中心の機能を強化し、IFB モジュールは、各 ID を対応する機能にバインドすることで、各 ID 間の接続を強化します。
実験結果では、Robin3D が、特定のタスクの微調整を必要とせずに、ScanRefer、Multi3DRefer、Scan2Cap、ScanQA、SQA3D を含む 5 つのベンチマークで以前の最良の方法を上回るパフォーマンスを示しています。
特にゼロターゲットケースを含む Multi3DRefer 評価では、Robin3D は [email protected] および [email protected] 指標でそれぞれ 7.8% および 7.3% の大幅な改善を達成しました。
Robin3D のリリースは、3D 大規模言語モデルの空間インテリジェンスにおける大幅な進歩を示し、将来的により多用途で強力な 3D エージェントを構築するための強固な基盤を築きます。
論文アドレス: https://arxiv.org/pdf/2410.00255
Robin3D の出現は、間違いなく 3D ビジョンと人工知能の分野に新たなブレークスルーをもたらし、その強力なパフォーマンスと幅広い応用の可能性は期待に値します。将来的には、Robin3D がより多くの分野で役割を果たし、3D インテリジェンスの急速な発展を促進すると信じています。 Downcodes の編集者は、この分野の最新の動向に今後も注目していきます。