Downcodes の編集者は、Meta、カリフォルニア大学バークレー校、およびニューヨーク大学の科学者が、大規模言語モデル (LLM) のパフォーマンス向上を目的として、「思考優先最適化」(TPO) と呼ばれる新技術を共同開発したことを知りました。このテクノロジーは、質問に答える前にモデルが一連の思考ステップを生成できるようにすることで AI の「思考」能力を向上させ、評価モデルを使用して最終的な答えの品質を最適化し、さまざまなタスクでパフォーマンスを向上させることができます。従来の「連鎖思考」テクノロジーとは異なり、TPO は応用範囲が広く、特に創造的な文章や常識的推論などにおいて大きな利点を発揮します。
最近、メタ、カリフォルニア大学バークレー校、ニューヨーク大学の科学者が協力して、思考嗜好最適化 (TPO) と呼ばれる新しいテクノロジーを開発しました。このテクノロジーの目標は、さまざまなタスクを実行する際の大規模言語モデル (LLM) のパフォーマンスを向上させ、AI が応答する前に応答をより慎重に検討できるようにすることです。
研究者たちは、思考には幅広い用途があるはずだと述べています。たとえば、クリエイティブライティングタスクでは、AI は内部の思考プロセスを使用して全体の構造とキャラクターの開発を計画できます。この方法は、以前の「思考連鎖」(CoT)プロンプト技術とは大きく異なります。後者は主に数学的および論理的なタスクで使用されますが、TPO はより幅広い用途に使用されます。研究者らは OpenAI の新しい o1 モデルについて言及しており、この思考プロセスは幅広いタスクにも役立つと考えています。
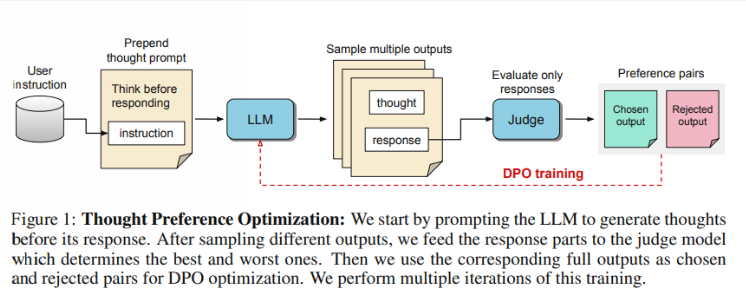
では、TPO はどのように機能するのでしょうか? まず、モデルは質問に答える前に一連の思考ステップを生成します。次に、複数の出力が作成され、思考ステップ自体ではなく、最終的な答えのみに基づいて評価モデルによって評価されます。最後に、これらの評価結果の好みの最適化を通じてモデルがトレーニングされます。研究者らは、モデルが暗黙的学習においてより効果的な推論能力を獲得できるように、思考プロセスを改善することで回答の質を向上させることができると期待しています。
テストでは、TPO を使用した Llama38B モデルは、明示的な推論を使用しないバージョンよりもベンチマークに従う一般的な命令で優れたパフォーマンスを示しました。 AlpacaEval ベンチマークと Arena-Hard ベンチマークでは、TPO の勝率はそれぞれ 52.5% と 37.3% に達しました。さらに興味深いのは、常識、マーケティング、健康など、通常は明確な思考を必要としない分野でも TPO が進歩していることです。
ただし、研究チームは、TPO はこれらのタスクでは基本モデルよりも実際にパフォーマンスが悪いため、現在の設定は数学的問題には適していないと指摘しました。これは、高度に専門化されたタスクには別のアプローチが必要になる可能性があることを示唆しています。将来の研究は、思考プロセスの長さの制御や、より大きなモデルに対する思考の影響などの側面に焦点を当てる可能性があります。
ハイライト:
研究チームは、タスク実行におけるAIの思考能力の向上を目的とした「Thinking Preference Optimization(TPO)」を開始した。
? TPO は評価モデルを使用して、回答前にモデルに思考ステップを生成させることで回答の質を最適化します。
テストによると、TPO は一般知識やマーケティングなどの分野では優れたパフォーマンスを発揮しますが、数学的なタスクではパフォーマンスが低いことが示されています。
全体として、TPO テクノロジーは大規模な言語モデルの改善に新たな方向性をもたらし、AI の思考能力を向上させる可能性には期待に値します。ただし、この技術にも限界があり、今後の研究でさらに改良し、応用範囲を拡大する必要があります。 Downcodes の編集者は、この分野の最新の開発に今後も注目し、読者にさらに刺激的なレポートをお届けしていきます。