Downcodes の編集者は、Alibaba Damo Academy と中国人民大学が共同で mPLUG-DocOwl1.5 と呼ばれる文書処理モデルをオープンソース化していることを知りました。このモデルは、OCR 認識なしでドキュメントの内容を理解でき、複数のベンチマーク テストで良好なパフォーマンスを示します。その中核は、マルチモーダル大規模言語モデル (MLLM) のリッチ テキスト イメージの構造理解を向上させる「統合構造学習」メソッドにあります。 。このモデルはコード、モデル、データセットを GitHub で公開しており、関連分野の研究に貴重なリソースを提供しています。
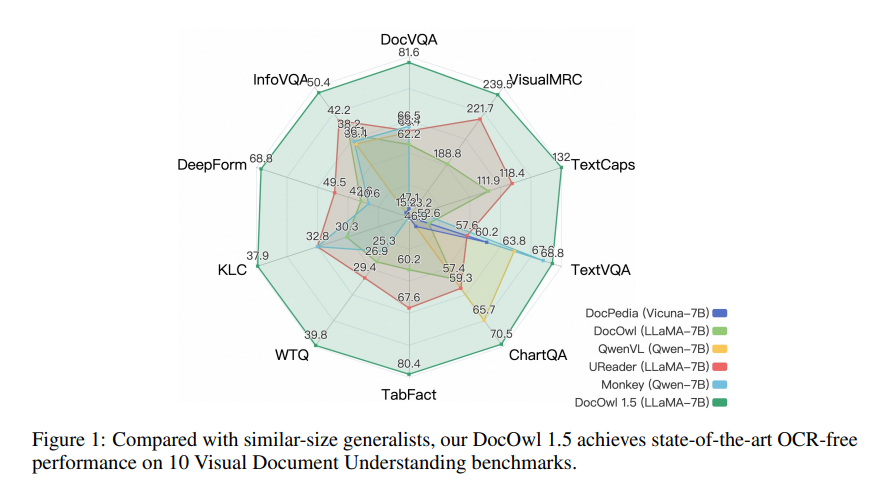
Alibaba Damo Academy と中国人民大学は最近、mPLUG-DocOwl1.5 と呼ばれる文書処理モデルを共同でオープンソース化しました。このモデルは、OCR 認識を使用せずに文書コンテンツを理解することに焦点を当てており、複数の視覚的文書理解ベンチマーク テストで優れたパフォーマンスを達成しました。
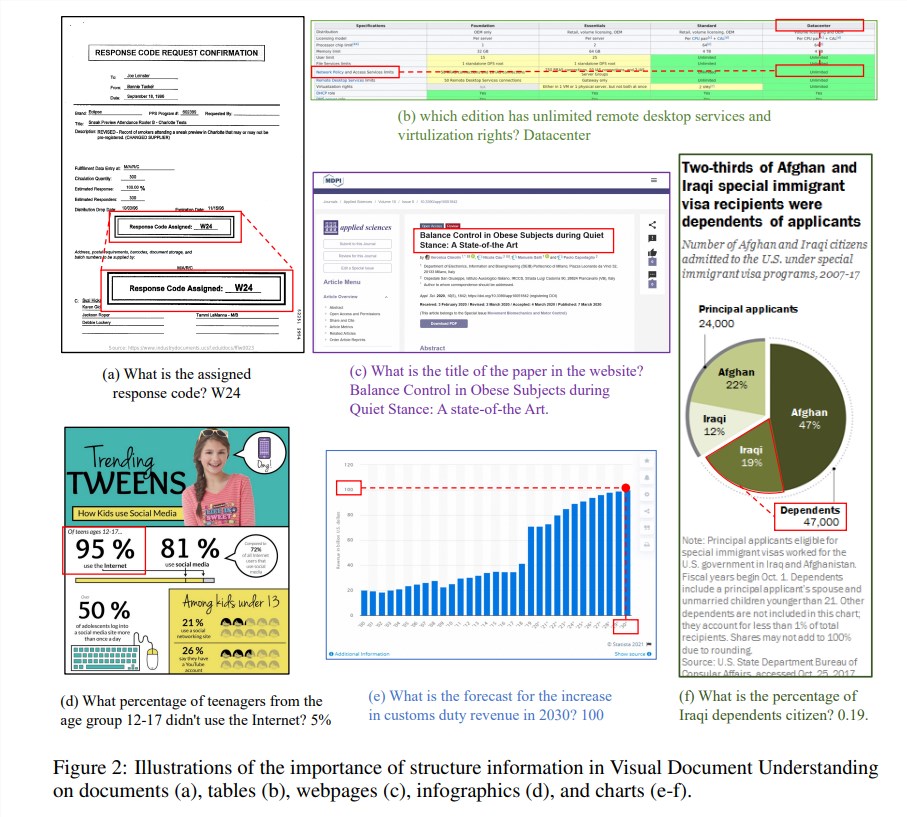
構造情報は、文書、表、グラフなどのテキストが豊富な画像のセマンティクスを理解するために重要です。 既存のマルチモーダル大規模言語モデル (MLLM) にはテキスト認識機能がありますが、リッチ テキスト ドキュメント イメージの一般的な構造を理解する機能が不足しています。この問題を解決するために、mPLUG-DocOwl1.5は視覚的な文書理解における構造情報の重要性を強調し、MLLMのパフォーマンスを向上させる「統合構造学習」を提案しています。
このモデルの「統合構造学習」は、文書、Web ページ、表、グラフ、自然画像の 5 つの領域をカバーしており、構造認識型の解析タスクや多粒度のテキスト位置決めタスクも含まれます。 構造情報をより適切にエンコードするために、研究者らは、シンプルで効果的な視覚からテキストへのモジュール H-Reducer を設計しました。これは、レイアウト情報を保存するだけでなく、畳み込みによって水平方向に隣接する画像パッチをマージすることで視覚特徴の長さを短縮します。高解像度の画像をより効率的に理解するための大規模な言語モデル。
さらに、構造学習をサポートするために、研究チームは DocStruct4M を構築しました。これは、公開されているデータセットに基づく 400 万サンプルを含む包括的なトレーニング セットで、構造認識テキスト シーケンスと多粒度テキスト境界ボックスのペアが含まれています。 文書分野における MLLM の推論能力をさらに刺激するために、彼らは 25,000 の高品質サンプルを含む推論微調整データ セット DocReason25K も構築しました。
mPLUG-DocOwl1.5 は 2 段階のトレーニング フレームワークを採用しており、最初に統合構造学習を実行し、次に複数の下流タスクでマルチタスク微調整を実行します。このトレーニング方法を通じて、mPLUG-DocOwl1.5 は 10 の視覚的文書理解ベンチマークで最先端のパフォーマンスを達成し、5 つのベンチマークで 7B LLM の SOTA パフォーマンスを 10 パーセント以上改善しました。
現在、mPLUG-DocOwl1.5のコード、モデル、データセットはGitHubで公開されています。
プロジェクトアドレス: https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5
論文アドレス: https://arxiv.org/pdf/2403.12895
mPLUG-DocOwl1.5 のオープンソースは、視覚的な文書理解の分野における研究と応用に新たな可能性をもたらします。その効率的なパフォーマンスと便利なアクセス方法は、開発者の注目と使用に値します。将来的には、このモデルがより実践的なシナリオで使用されることが期待されます。