Downcodes の編集者が、スイス連邦工科大学ローザンヌ校 (EPFL) の最新の研究結果について学びましょう。この研究では、大規模言語モデル (LLM) の 2 つの主流の適応トレーニング手法であるコンテキスト学習 (ICL) と命令微調整 (IFT) を詳細に比較し、MT-Bench ベンチマークを使用してモデルの追従能力を評価します。説明書。研究結果は、2 つの方法がさまざまなシナリオでそれぞれの利点を持ち、LLM トレーニング方法の選択に貴重な参考となることを示しています。
スイスのローザンヌ工科大学(EPFL)の最近の研究では、大規模言語モデル(LLM)向けの 2 つの主流の適応トレーニング方法、文脈学習(ICL)と命令微調整(IFT)を比較しました。研究者らは、MT-Bench ベンチマークを使用してモデルの指示に従う能力を評価したところ、特定の状況下では両方の方法のパフォーマンスが良くなったり悪くなったりすることがわかりました。
研究によると、利用可能なトレーニング サンプルの数が少ない場合 (たとえば、50 個以下)、ICL と IFT の効果は非常に近いことがわかりました。これは、データが限られている場合、ICL が IFT の代替となる可能性があることを示唆しています。
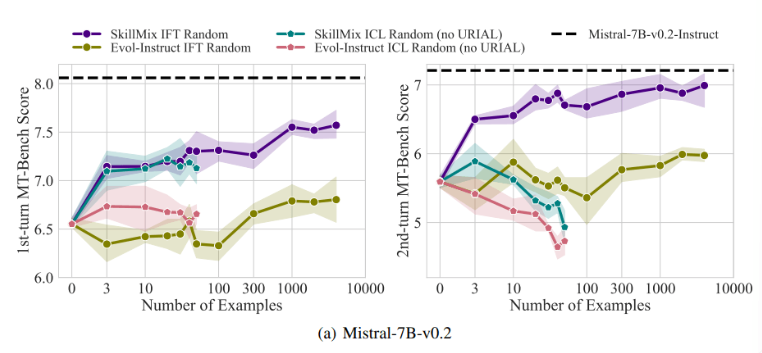
ただし、複数ターンの対話シナリオなど、タスクの複雑さが増すにつれて、IFT の利点が明らかになります。研究者らは、ICL モデルは単一サンプルのスタイルに過剰適合する傾向があり、その結果、複雑な会話を処理する際のパフォーマンスが低下する、あるいは基本モデルよりもさらに悪くなる可能性があると考えています。
この研究では、3 つのサンプルとルールに従う命令のみを使用して基本言語モデルをトレーニングする URIAL メソッドも検証しました。 URIAL は一定の成果を上げていますが、IFT で学習されたモデルと比較するとまだ差があります。 EPFL の研究者は、サンプル選択戦略を改善し、モデルの微調整に近づけることで URIAL のパフォーマンスを向上させました。これは、ICL、IFT、および基本的なモデルのトレーニングにおける高品質のトレーニング データの重要性を強調しています。
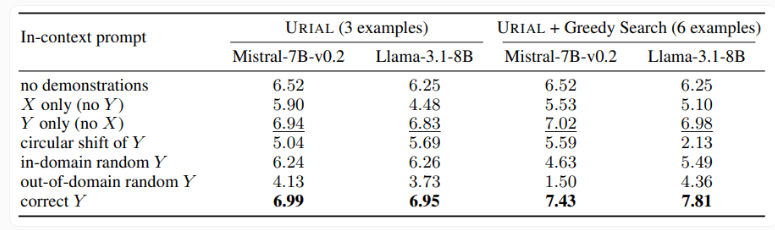
さらに、この研究では、デコードパラメータがモデルのパフォーマンスに大きな影響を与えることも判明しました。これらのパラメーターは、モデルがテキストを生成する方法を決定し、基本的な LLM と URIAL でトレーニングされたモデルの両方にとって重要です。
研究者らは、適切なデコードパラメータが与えられれば、基本モデルでもある程度の指示に従うことができると指摘しています。
この研究の重要性は、特にトレーニング サンプルが限られている場合に、文脈学習によって言語モデルを迅速かつ効率的に調整できることが明らかになったということです。ただし、複数ターンにわたる会話などの複雑なタスクの場合は、コマンドを微調整する方が依然として良い選択です。
データセットのサイズが増加するにつれて、IFT のパフォーマンスは向上し続けますが、ICL のパフォーマンスは一定のサンプル数に達すると安定します。研究者らは、ICL と IFT のどちらを選択するかは、利用可能なリソース、データ量、特定のアプリケーション要件などのさまざまな要因によって決まることを強調しています。どちらの方法を選択する場合でも、高品質のトレーニング データが重要です。
全体として、この EPFL 研究は、大規模言語モデルのトレーニング方法の選択について新たな洞察を提供し、将来の研究の方向性を示しています。 ICL または IFT を選択するには、特定の状況に基づいてメリットとデメリットを比較検討する必要があり、高品質のデータが常に鍵となります。この研究が、誰もが大規模な言語モデルをよりよく理解し、適用できるようになれば幸いです。