Downcodes のエディターは、Zhiyuan Research Institute がリリースした最新のマルチモーダル ワールド モデルである Emu3 について学習します。 Emu3 は、独自の「次のトークン予測」機能を利用して、テキスト、画像、ビデオの 3 つのモダリティで画期的な理解と生成機能を実現します。高品質の画像と滑らかで自然なビデオを生成できるだけでなく、そのパフォーマンスは多くの有名なオープンソース モデルを上回ります。 Emu3 のオープンソースの性質も、マルチモーダル AI の開発に新たな活力をもたらします。その背後にある技術革新と将来の可能性を探ってみましょう。
Zhiyuan Research Institute は、新世代のマルチモーダル ワールド モデル Emu3 を正式にリリースしました。このモデルの最大のハイライトは、テキスト、画像、ビデオの 3 つの異なるモードで次のトークンを予測できることです。

画像生成に関しては、Emu3 は視覚的なトークン予測に基づいて高品質の画像を生成できます。これは、ユーザーが柔軟な解像度とさまざまなスタイルを期待できることを意味します。

ビデオ生成に関しては、Emu3 はノイズを通じてビデオを生成する他のモデルとは異なり、まったく新しい方法で動作します。Emu3 は逐次予測を通じてビデオを直接生成します。この技術の進歩により、ビデオ生成がよりスムーズかつ自然になりました。

画像生成、ビデオ生成、視覚言語理解などのタスクにおいて、Emu3 のパフォーマンスは、SDXL、LLaVA、OpenSora などの多くのよく知られたオープン ソース モデルのパフォーマンスを上回ります。その背後には、ビデオと画像を個別のトークンに変換できる強力なビジュアル トークナイザーがあり、この設計はテキスト、画像、ビデオを統合処理するための新しいアイデアを提供します。
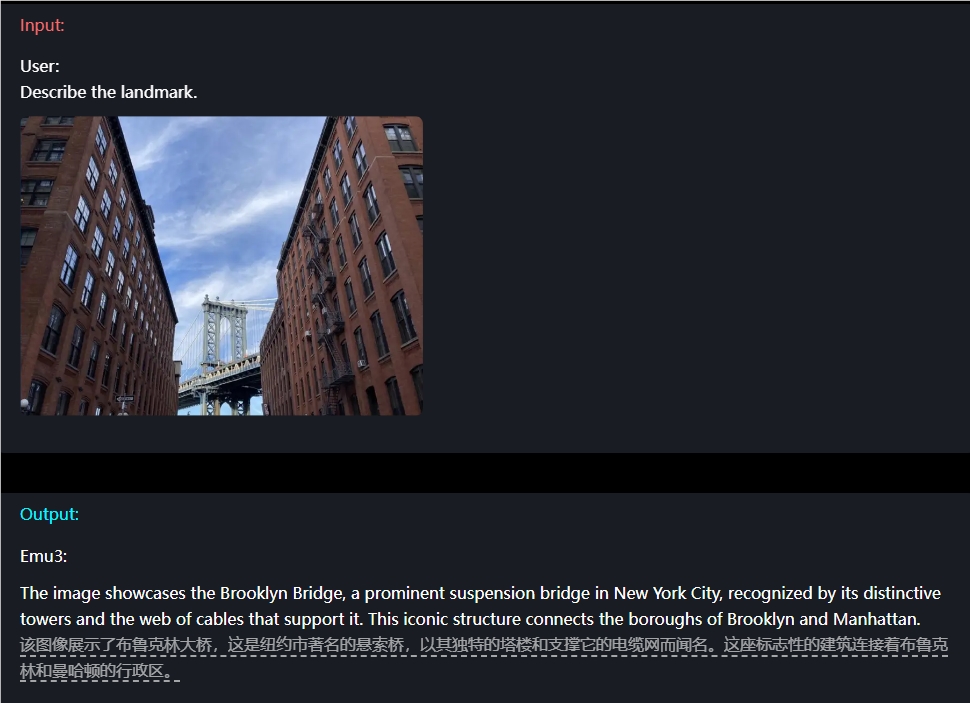
例えば、画像の理解に関しては、ユーザーは質問を入力するだけで済み、Emu3 は画像の内容を正確に記述することができます。
Emu3 にはビデオ予測機能もあります。ビデオが与えられると、Emu3 は既存のコンテンツに基づいて次に何が起こるかを予測できます。これにより、環境、人間、動物の行動をシミュレートする強力な機能を発揮し、ユーザーがより現実的なインタラクティブな体験を体験できるようになります。

さらに、Emu3 の設計の柔軟性は新鮮です。人間の好みに合わせて直接最適化できるため、生成されたコンテンツはユーザーの期待にさらに沿うものになります。さらに、Emu3 はオープンソース モデルとして、技術コミュニティで熱い議論を集めており、この成果がマルチモーダル AI の開発パターンを完全に変えると多くの人が信じています。
プロジェクトURL:https://emu.baai.ac.cn/about
論文: https://arxiv.org/pdf/2409.18869
ハイライト:
Emu3 は、次のトークンの予測を通じて、テキスト、画像、ビデオのマルチモーダルな理解と生成を実現します。
複数のタスクにおいて、Emu3 のパフォーマンスは多くのよく知られたオープンソース モデルのパフォーマンスを上回り、その強力な機能を実証しました。
Emu3 の柔軟な設計とオープンソース機能は、開発者に新たな機会を提供し、マルチモーダル AI の革新と開発を促進することが期待されています。
Emu3 の登場は、マルチモーダル AI の分野における新たなマイルストーンを示します。その強力なパフォーマンス、柔軟な設計、オープンソースの機能は、間違いなく将来の AI の開発に大きな影響を与えるでしょう。エミュ3がより多くの分野で活用され、人類にさらなる便利さと驚きをもたらすことを楽しみにしています。