Downcodes の編集者は、イェール大学での画期的な研究で AI モデル トレーニングの秘密が明らかになった、つまりデータの複雑さは高いほど優れているわけではなく、最適な「カオスの端」状態が存在することを知りました。研究チームはセルオートマトンモデルを巧みに利用して実験を行い、複雑さの異なるデータがAIモデルの学習効果に及ぼす影響を調査し、目を引く結論に達しました。
イェール大学の研究チームは最近、画期的な研究結果を発表し、AI モデルのトレーニングにおける重要な発見を明らかにしました。つまり、AI 学習効果が最も優れているデータは単純でも複雑でもありませんが、最適な複雑さのレベルが存在します。混沌の端。
研究チームは、基本セル オートマトン (ECA) を使用して実験を行いました。ECA は、各ユニットの将来の状態がそれ自身と隣接する 2 つのユニットの状態のみに依存する単純なシステムです。ルールが単純であるにもかかわらず、このようなシステムは、単純なものから非常に複雑なものまで、さまざまなパターンを生成できます。次に研究者らは、推論タスクとチェスの手の予測に関するこれらの言語モデルのパフォーマンスを評価しました。
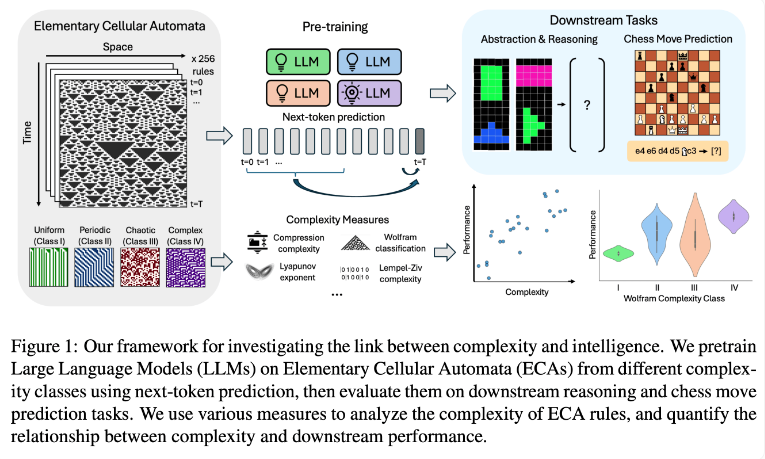
研究結果は、より複雑な ECA ルールに基づいてトレーニングされた AI モデルが、後続のタスクでより優れたパフォーマンスを発揮することを示しています。特に,Wolfram分類のクラスIV ECAで訓練されたモデルは最高のパフォーマンスを示した。このようなルールによって生成されるパターンは、完全に秩序立ったものでも、完全に混沌としたものでもなく、むしろ構造化された複雑さを示します。
研究者らは、モデルが単純すぎるパターンにさらされると、モデルは単純な解決策しか学習しないことが多いことを発見しました。対照的に、より複雑なパターンでトレーニングされたモデルは、単純なソリューションが利用可能な場合でも、より高度な処理能力を開発します。研究チームは、この学習された表現の複雑さが、モデルが知識を他のタスクに伝達できるかどうかの重要な要素であると推測しています。
この発見は、GPT-3 や GPT-4 などの大規模な言語モデルがなぜ非常に効率的であるかを説明する可能性があります。研究者らは、これらのモデルのトレーニングに使用された膨大で多様なデータが、研究での複雑な ECA パターンと同様の効果を生み出した可能性があると考えています。
この研究は、AI モデルのトレーニングに関する新しいアイデアと、大規模な言語モデルの強力な機能を理解するための新しい視点を提供します。将来的には、トレーニング データの複雑さをより正確に制御することで、AI モデルのパフォーマンスと汎化機能をさらに向上できる可能性があります。 Downcodes の編集者は、この研究結果が人工知能の分野に大きな影響を与えると信じています。