Downcodes の編集者は、北京知源人工知能研究所が多くの大学と協力して、Video-XL と呼ばれる超長時間ビデオ理解のための大規模モデルを立ち上げたことを知りました。このモデルは 10 分を超える長いビデオの処理で優れたパフォーマンスを発揮し、複数のベンチマークでトップの地位を獲得し、強力な汎化機能と処理効率を実証しています。 Video-XL は、言語モデルを使用して長いビジュアル シーケンスを圧縮し、「干し草の山から針を見つける」などのタスクでほぼ 95% の精度を達成します。2048 フレームの入力を処理するには、80G のビデオ メモリを搭載したグラフィック カードのみが必要です。このモデルのオープンソースは、世界的なマルチモーダルビデオ理解研究コミュニティの協力と発展を促進します。
北京知源人工知能研究所は、上海交通大学、中国人民大学、北京大学、北京郵電大学などの大学と協力して、Video-XLと呼ばれる大規模な超長時間ビデオ理解モデルを立ち上げた。このモデルは、マルチモーダル大規模モデルの中核機能を示す重要なデモンストレーションであり、汎用人工知能 (AGI) に向けた重要な一歩です。既存のマルチモーダル大規模モデルと比較して、Video-XL は 10 分を超える長いビデオを処理する際に優れたパフォーマンスと効率を示します。

Video-XL は、言語モデル (LLM) のネイティブ機能を利用して長いビジュアル シーケンスを圧縮し、短いビデオを理解する能力を保持し、長いビデオの理解において優れた一般化機能を示します。このモデルは、複数の主流の長時間ビデオ理解ベンチマークの複数のタスクで 1 位にランクされています。 Video-XL は、2048 フレーム入力を処理し、1 時間のビデオをサンプルし、ビデオの「干し草の山を針で探す」タスクでほぼ 95% を達成するには、80G ビデオ メモリを搭載したグラフィック カードのみが必要です。 % 正確さ。
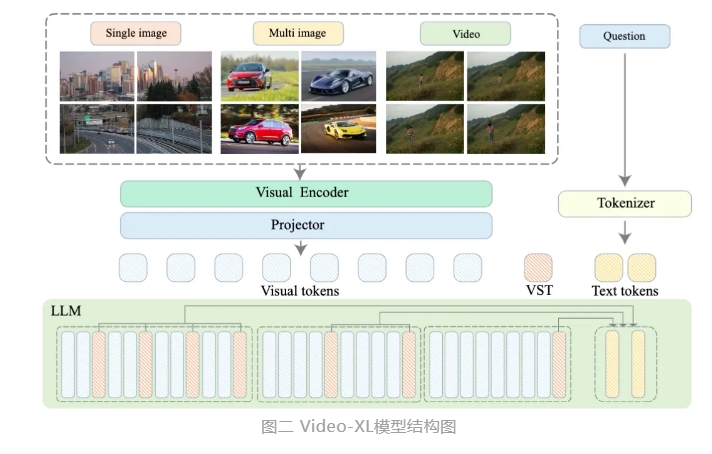
Video-XL は、映画の要約、ビデオの異常検出、広告配置の検出などのアプリケーション シナリオで広範な応用価値を示し、長時間のビデオを理解するための強力なアシスタントになることが期待されています。このモデルの発表は、長時間ビデオ理解テクノロジーの効率と精度における重要な一歩を示し、将来的には長時間ビデオ コンテンツの自動処理と分析に対する強力な技術サポートを提供します。
現在、Video-XL のモデル コードは、グローバルなマルチモーダル ビデオ理解研究コミュニティでの協力と技術共有を促進するためにオープンソース化されています。
論文タイトル: Video-XL: 時間スケールのビデオ理解のための超ロングビジョン言語モデル
論文リンク: https://arxiv.org/abs/2409.14485
モデルリンク: https://huggingface.co/sy1998/Video_XL
プロジェクトリンク: https://github.com/VectorSpaceLab/Video-XL
Video-XL のオープンソースは、長時間ビデオ理解の分野における研究と応用に新たな可能性をもたらし、その効率性と正確性により、関連技術のさらなる開発が促進され、将来的にはより多くの応用シナリオに技術サポートが提供されます。将来的には、Video-XL をベースにしたさらに革新的なアプリケーションが登場することを楽しみにしています。