Downcodes の編集者が、ドイツのダルムシュタット工科大学の最新研究を紹介します。この研究では、単純な視覚推論タスクにおける現在の最先端の AI 画像モデルのパフォーマンスを評価するためのテスト ツールとして Bongard 問題を使用しました。研究結果は驚くべきもので、GPT-4oのようなトップマルチモーダルモデルの精度さえも予想よりもはるかに低く、既存のAI視覚能力評価基準について深く反省するきっかけとなった。
ドイツのダルムシュタット工科大学の最新の研究では、考えさせられる現象が明らかになりました。それは、最も高度な AI 画像モデルであっても、単純な視覚的推論タスクに直面すると重大な間違いを犯す可能性があるということです。今回の研究結果は、AIの視覚能力の評価基準について新たな考え方を提案した。
研究チームは、ロシアの科学者ミハイル・ボンガード氏が設計したボンガード問題をテストツールとして使用した。このタイプの視覚パズルは、2 つのグループに分けられた 12 枚の単純な画像で構成されており、2 つのグループを区別するルールを特定する必要があります。この抽象的な推論タスクはほとんどの人にとって難しくありませんが、AI モデルのパフォーマンスは驚くべきものでした。
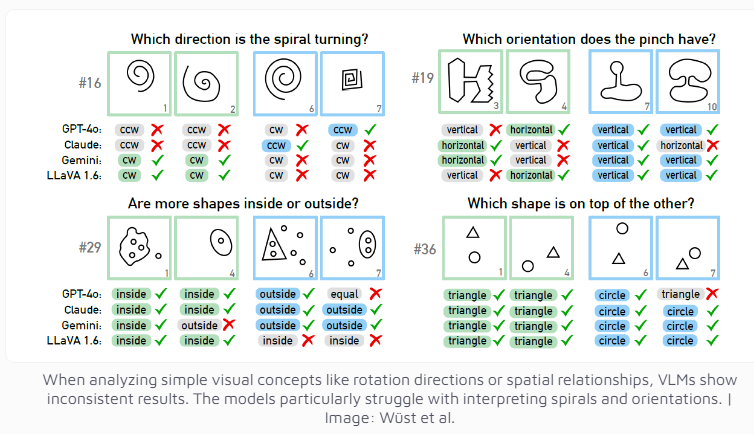
現在最も先進的であると考えられているマルチモーダル モデル GPT-4o でさえ、100 個の視覚パズルのうち 21 個しか解決できませんでした。 Claude、Gemini、LLaVA などの他のよく知られた AI モデルのパフォーマンスはさらに満足のいくものではありません。これらのモデルでは、垂直線や水平線などの基本的な視覚概念を識別したり、らせんの方向を判断したりすることが非常に困難です。
研究者らは、複数の選択肢が提供された場合でも、AI モデルのパフォーマンスはわずかにしか改善されないことを発見しました。可能な答えの数に対する厳格な制限の下でのみ、GPT-4 とクロードはパズルの成功率をそれぞれ 68 問と 69 問に向上させました。研究チームは、4つの具体的なケースを詳細に分析した結果、AIシステムは思考や推論の段階に到達する前に、基本的な視覚認識レベルで問題を抱えている場合があるが、具体的な理由を特定するのはまだ難しいことを発見した。
この研究は、AI システムの評価基準について考えるきっかけにもなります。研究チームは次のように指摘しました: 視覚言語モデルはなぜ確立されたベンチマークではうまく機能するのに、一見単純なボンガード問題では苦戦するのでしょうか? これらのベンチマークは現実世界の推論能力を評価する上でどの程度意味があるのでしょうか? 現在の AI 評価システムがそうであることを示唆しています。 AI の視覚的推論能力をより正確に測定するには、再設計する必要があるかもしれません。
この研究は、現在の AI テクノロジーの限界を実証するだけでなく、AI の視覚機能の将来の開発への道も示しています。私たちは、AI の急速な進歩を歓迎する一方、AI の基本的な認知能力にはまだ改善の余地があることを明確に認識する必要があることを思い出させます。
この研究は、AI モデルの視覚的推論にはまだ多くの改善の余地があり、AI の認知能力を向上させるためには、より効果的な評価方法と技術的なブレークスルーが将来必要であることを明確に示しています。 Downcodes の編集者は今後も AI 分野の最先端の進歩に注目し、より刺激的なレポートをお届けしていきます。