Downcodes のエディターでは、大規模言語モデル (LLM) の効率を向上させる革新的なテクノロジーである Q-Sparse について学習できます。 LLM の強力な自然言語処理機能は多くの注目を集めていますが、その高い計算コストとメモリ使用量が実際のアプリケーションでは常にボトルネックとなっています。 Q-Sparse は、賢いスパース化手法を使用して、モデルのパフォーマンスを確保しながら推論効率を大幅に向上させ、LLM の広範なアプリケーションへの道を開きます。この記事では、Q-Sparse のコア技術、利点、実験的検証結果を深く掘り下げ、LLM の効率向上におけるその大きな可能性を示します。
人工知能の世界では、大規模言語モデル (LLM) がその優れた自然言語処理能力で知られています。ただし、これらのモデルを実際のアプリケーションに展開するには、主に推論段階での高い計算コストとメモリ使用量が原因で、大きな課題に直面しています。この問題を解決するために、研究者は LLM の効率を向上させる方法を模索してきました。最近、Q-Sparse と呼ばれる手法が注目を集めています。
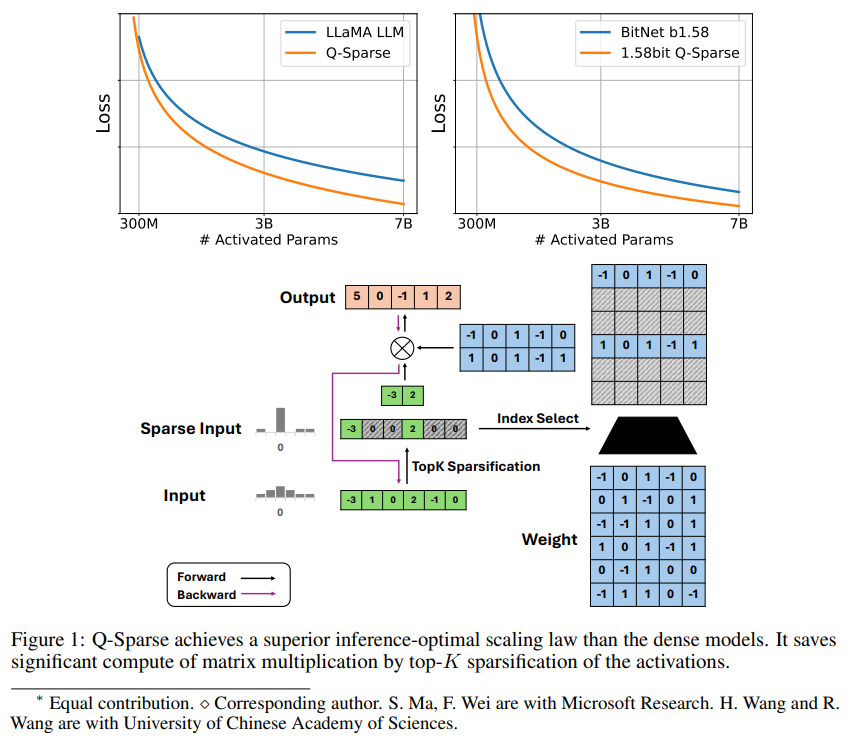
Q-Sparse は、アクティベーションに Top-K スパース化を適用し、トレーニングにパススルー推定器を適用することで、LLM の完全にスパースなアクティベーションを実現する、シンプルですが効果的な方法です。これは、推論時の効率が大幅に向上することを意味します。主な研究結果は次のとおりです。
Q-Sparse は、ベースライン LLM と同等の結果を維持しながら、より高い推論効率を実現します。
スパースアクティベーションLLMに適した推論的最適展開規則を提案する。
Q-Sparse は、ゼロからのトレーニング、既製の LLM の継続的なトレーニング、微調整など、さまざまな設定で機能します。
Q-Sparse は、完全精度および 1 ビット LLM (例: BitNet b1.58) で動作します。
スパースアクティベーションの利点
スパース性は 2 つの方法で LLM の効率を向上させます。1 つ目は、スパース性によりゼロ要素が計算されないため、行列乗算の計算量を削減できます。2 つ目は、スパース性により入出力 (I/O) 送信の量が削減できることです。これは、LLM の推論フェーズにおける主なボトルネックです。
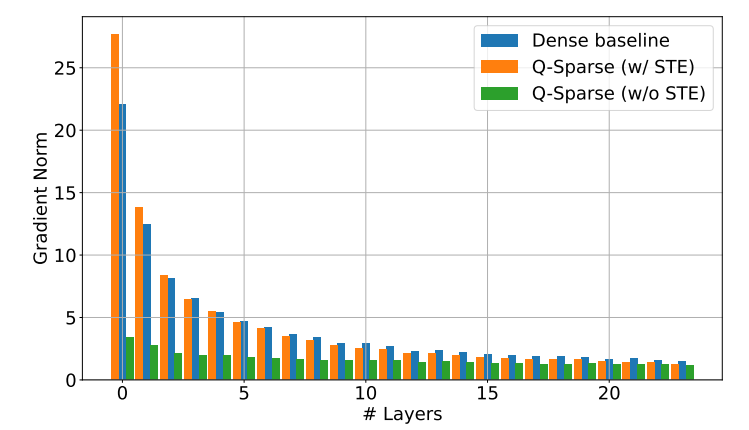
Q-Sparse は、各線形投影に上位 K のスパース化関数を適用することにより、アクティベーションの完全なスパース性を実現します。バックプロパゲーションの場合、活性化の勾配はパススルー推定器を使用して計算されます。さらに、活性化のスパース性をさらに改善するために、2 乗 ReLU 関数が導入されています。
実験による検証
研究者らは、一連の拡張実験を通じて、まばらに活性化された LLM の拡張則を研究し、いくつかの興味深い発見に至りました。
スパース アクティベーション モデルのパフォーマンスは、モデル サイズとスパース率が増加するにつれて向上します。
スパース率 S が固定されている場合、スパース活性化モデルのパフォーマンスは、べき乗則に従ってモデル サイズ N に応じてスケールされます。
固定パラメーター N を指定すると、スパース活性化モデルのパフォーマンスはスパース率 S に応じて指数関数的にスケールします。
Q-Sparse は、ゼロからのトレーニングだけでなく、既製の LLM の継続的なトレーニングや微調整にも使用できます。トレーニングの継続と微調整の設定では、研究者らは最初からトレーニングする場合と同じアーキテクチャとトレーニング プロセスを使用しました。唯一の違いは、事前トレーニングされた重みでモデルを初期化し、スパース関数でトレーニングを継続できるようにすることでした。
研究者は、LLM の効率をさらに向上させるために、1 ビット LLM (BitNet b1.58 など) および混合エキスパート (MoE) で Q-Sparse を使用することを検討しています。さらに、彼らは Q-Sparse をバッチ モードと互換性のあるものにすることに取り組んでおり、これにより LLM のトレーニングと推論により高い柔軟性が提供されます。
Q-Sparse テクノロジーの出現は、LLM の効率性の問題を解決するための新しいアイデアを提供し、コンピューティング コストとメモリ使用量の削減に大きな可能性を秘めており、より多くの分野で LLM の適用が促進されることが期待されています。将来的には、LLM のパフォーマンスと効率をさらに向上させるために、Q-Sparse に基づくさらに多くの研究結果が現れると考えられています。