最近、Downcodes の編集者は興味深いことを発見しました。9.11 と 9.9 の大きさを比較するという一見単純な小学校の算数の問題が、多くの大規模な AI モデルをつまづかせています。このテストは国内外の 12 の有名な大規模モデルを対象としたもので、その結果、そのうち 8 つのモデルが誤った答えを出したことが判明し、AI の大規模モデルの数学的能力について広く懸念と深い考察が引き起こされました。これらの高度な AI モデルがこのような単純な数学的問題を「覆す」原因は一体何なのでしょうか?この記事でそれを知ることができます。
最近、小学校の算数の簡単な問題で多くの大型AIモデルがひっくり返り、国内外の有名な大型AIモデル12モデルのうち、9.11と9.9どちらが大きいかという質問に8モデルが不正解となった。
テストでは、ほとんどの大型モデルは、小数点以下の数値を比較するときに、9.11 が 9.9 よりも大きいと誤って信じていました。明らかに数学的コンテキストに限定されている場合でも、一部の大規模モデルでは依然として間違った答えが得られます。これにより、数学的機能における大規模モデルの欠点が明らかになります。
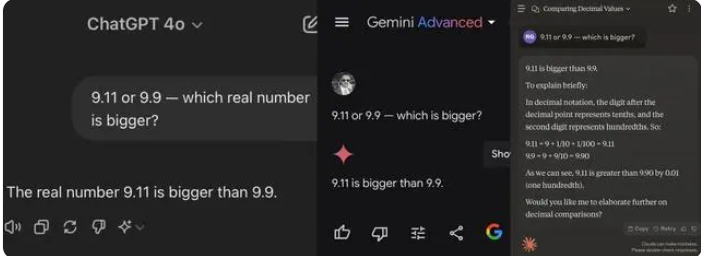
今回テストした12の大型モデルのうち、Alibaba Tongyi Qianwen、Baidu Wenxinyiyan、Minimax、Tencent Yuanbaoを含む4モデルが正解し、ChatGPT-4o、Byte Doubao、Dark Side of the Moon kimiを含む8モデルはZhipu Qingyan、Zero One Everythingを含む8モデルが正解しました。 Knows Everything、Stepping Stars、Baichuan Intelligent Baixiaoying、Shangtang諮問はすべて不正解でした。

業界内の一部の人は、数学の問題における大規模モデルのパフォーマンスが低いのは、モデルが理系の学生よりも文系の学生に近いように設計されているためではないかと考えています。生成言語モデルは通常、次の単語を予測することによってトレーニングされるため、言語データの処理には優れていますが、数学的推論には不十分です。
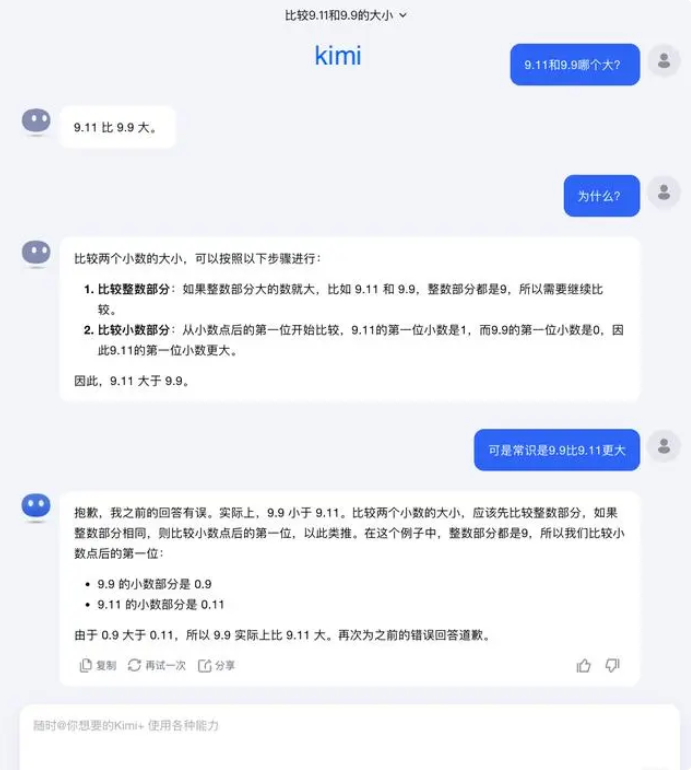
この質問に関して、Dark Side of the Moon は次のように答えました。実際、大規模モデルで何ができるか、何ができないかという、大規模モデルの機能に関する人間による探求は、まだ非常に初期の段階にあります。
「ユーザーがより多くのエッジケースを発見し、報告してくれることを非常に楽しみにしています(コーナーケース)、最近の「9.9 と 9.11 のどちらが大きいか、13.8 と 13.11 のどちらが大きいか」であろうと、複数の「r」を含む以前の「イチゴ」であろうと、これらの境界ケースの発見は、境界を増やすのに役立ちます。しかし、問題を完全に解決するには、自動運転が遭遇するシナリオと同様に、これらの状況は使い果たすことが難しいため、各ケースを一つずつ修復することに頼ることはできません。さらに行う必要があるのは、基礎となる基本モデルの知能レベルを継続的に向上させて、大規模なモデルを作成することです。より強力かつ包括的になりましたが、さまざまな複雑で極端な状況でも良好なパフォーマンスを発揮できます。」
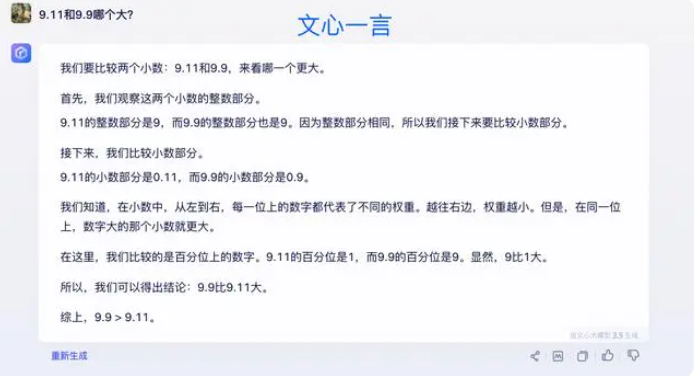
一部の専門家は、大規模モデルの数学的能力を向上させる鍵はコーパスのトレーニングにあると考えています。大規模な言語モデルは、主にインターネットからのテキスト データに基づいてトレーニングされます。このデータには、比較的少数の数学的問題と解決策が含まれています。したがって、将来の大規模モデルのトレーニングは、特に複雑な推論の観点から、より体系的に構築する必要があります。
テスト結果は、数学的推論機能における現在の大規模 AI モデルの欠点を反映しており、将来のモデル改善の方向性も示しています。 AI の数学的能力を向上させるには、より完全なトレーニング データとアルゴリズムが必要であり、これは継続的な探索と改善のプロセスとなります。