近年、マルチモーダルな大型モデルが急速に発展し、優れたモデルが数多く登場しています。ただし、既存のモデルのほとんどは視覚エンコーダーに依存しており、トレーニングの分離によって引き起こされる視覚誘導バイアスの問題が発生し、効率とパフォーマンスが制限されます。 Downcodes のエディターは、Zhiyuan Research Institute が大学と共同で立ち上げた新しいビジュアル言語モデル EVE を提供します。これはコーダーレス アーキテクチャを採用しており、複数のベンチマーク テストで優れた結果を達成しており、マルチモーダル モデルの開発に新たな機会を提供しています。 .アイデア。
最近、マルチモーダル大規模モデルの研究と応用において大きな進歩が見られました。 OpenAI、Google、Microsoftなどの外国企業は一連の先進的なモデルを発売し、Zhipu AIやStep Starなどの国内企業はこの分野で躍進を遂げている。これらのモデルは通常、ビジュアル エンコーダーに依存して視覚的特徴を抽出し、それらを大規模な言語モデルと結合しますが、トレーニングの分離によって引き起こされる視覚誘導バイアスの問題があり、マルチモーダルな大規模モデルの展開効率とパフォーマンスが制限されます。
これらの問題を解決するために、Zhiyuan Research Institute は、大連理工大学、北京大学、その他の大学と協力して、新世代のコーダーフリーのビジュアル言語モデル EVE を立ち上げました。 EVE は、洗練されたトレーニング戦略と追加の視覚的監視を通じて、視覚言語表現、調整、および推論を統合された純粋なデコーダー アーキテクチャに統合します。 EVE は、公開データを使用することで、複数の視覚言語ベンチマークで優れたパフォーマンスを発揮し、主流のエンコーダーベースのマルチモーダル手法に迫る、またはそれを上回るパフォーマンスを発揮します。
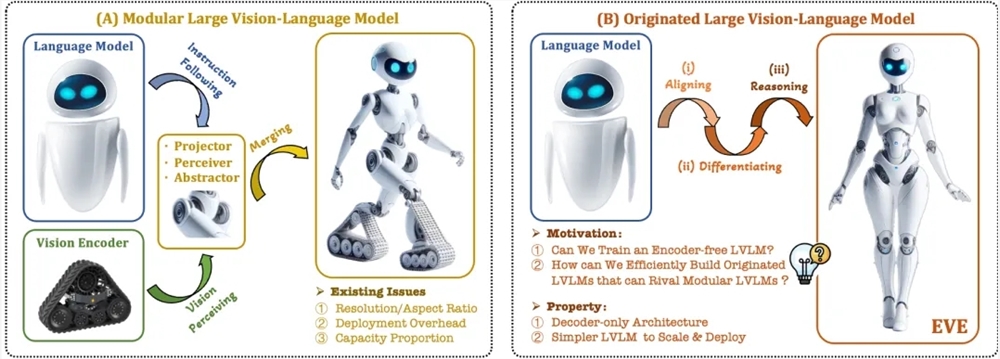
EVE の主な機能は次のとおりです。
ネイティブビジュアル言語モデル: ビジュアルエンコーダーを削除し、あらゆる画像アスペクト比を処理します。これは、同じタイプの Fuyu-8B モデルよりも大幅に優れています。
データとトレーニングのコストが低い: 事前トレーニングでは OpenImages、SAM、LAION などの公開データが使用され、トレーニング時間は短くなります。
透過的で効率的な探索: 純粋なデコーダーのネイティブ マルチモーダル アーキテクチャに効率的で透過的な開発パスを提供します。
モデル構造:
パッチ埋め込み層: 単一の畳み込み層と平均プーリング層を通じて画像の 2D 特徴マップを取得し、ローカル特徴とグローバル情報を強化します。
パッチ調整レイヤー: マルチレイヤー ネットワークのビジュアル機能を統合して、ビジュアル エンコーダー出力とのきめ細かい調整を実現します。
トレーニング戦略:
大規模な言語モデルによってガイドされる事前トレーニング段階: 視覚と言語の間の最初の接続を確立します。
生成的な事前トレーニング段階: 視覚言語コンテンツを理解するモデルの能力を向上させます。
監視付き微調整フェーズ: 言語の指示に従い、会話パターンを学習するモデルの能力を調整します。
定量的分析: EVE は複数のビジュアル言語ベンチマークで良好なパフォーマンスを示し、主流のエンコーダーベースのさまざまなビジュアル言語モデルと同等です。特定の命令に正確に応答するという課題にもかかわらず、EVE は効率的なトレーニング戦略を通じて、エンコーダー ベースを備えたビジュアル言語モデルに匹敵するパフォーマンスを達成しています。
EVE は、エンコーダレスのネイティブ ビジュアル言語モデルの可能性を実証しており、今後はさらなるパフォーマンスの向上、エンコーダレス アーキテクチャの最適化、ネイティブ マルチモーダルの構築を通じてマルチモーダル モデルの開発を推進していく可能性があります。モデル。
論文アドレス: https://arxiv.org/abs/2406.11832
プロジェクトコード: https://github.com/baaivision/EVE
モデルアドレス: https://huggingface.co/BAAI/EVE-7B-HD-v1.0
全体として、EVE モデルの出現は、マルチモーダル大規模モデルの開発に新たな方向性と可能性をもたらし、その効率的なトレーニング戦略と優れたパフォーマンスは注目に値します。今後のEVEモデルがより多くのフィールドでその強力な能力を発揮できることを期待しています。