OpenAIの謎に満ちた「Strawberry」プロジェクトがついに公開!以前は Q* というコード名で呼ばれていたプロジェクトが、「Strawberry」という名前で再び登場しました。その強力な機能は驚くべきものです。AI は独自にタスクを計画し、オンラインで情報を検索し、さらには詳細な調査を行うこともできます。マスク氏もそれをからかったほどであり、その影響力の大きさが伺える。 Downcodes のエディターは、この印象的なプロジェクトについて詳しく学び、それがどんな魔法を持っているかを確認するためにあなたを導きます。
最近、OpenAI は「Strawberry」プロジェクトの謎を静かに明らかにしました。以前は Q* として知られ、現在は Strawberry として再起動されたこのプロジェクトでは、AI が事前にタスクを計画し、オンラインで自律的に情報を収集し、さらには詳細な調査を行うことができると言われています。
テクノロジー界の重鎮であるマスク氏も関与せずにはいられなかったとコメントし、「当初はAIの終焉はペーパークリップの惨事だと思っていたが、今では終わりのないイチゴかもしれないと思っている。フィールド。」
Project Strawberry に対する外部の関心にもかかわらず、OpenAI はその運営の詳細については口を閉ざしてきました。このプロジェクトの開発過程は社内で極秘に扱われ、リリース時期さえも謎に包まれているほどだ。
最近の社内会議で、OpenAI は人間とほぼ同等の推論能力を備えた Project Strawberry のデモ バージョンを披露しました。これは、最近発表された AGI ロードマップと一致しており、人々は OpenAI がより大きな動きを計画しているのではないかと疑問に思っています。
ストロベリー モデルの設計コンセプトは、AI がクエリの回答を生成するだけでなく、事前に計画を立て、自律的かつ確実にインターネットを閲覧し、いわゆる「詳細な調査」を実行できるようにすることです。現時点では、この機能は AI 分野では初のものです。
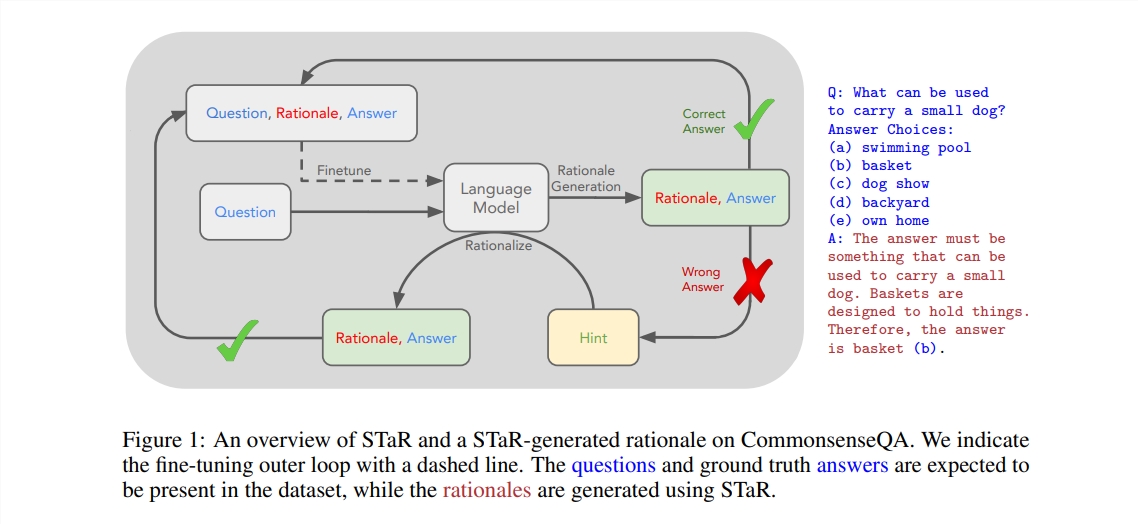
この件に詳しい関係者らによると、OpenAIのStrawberryプロジェクトは、スタンフォード大学が開発した手法「Self-Teaching Reasoner」(略してSTaR)にやや似ているという。 STAR は学習データを繰り返し作成することで自己改善を実現します。
論文アドレス: https://arxiv.org/pdf/2203.14465
現在、AI に推論プロセスを生成させる方法はコストがかかるか、精度が犠牲になっています。しかし、STAR テクノロジーを使用すると、少数の推論例と大量の非推論データを繰り返し使用することで AI 自体を改善できます。
STaR テクノロジーのワークフローは次のとおりです。まず、AI が多くの質問に答えようとし、推論プロセスを生成します。答えが間違っている場合は、正しい答えを知って推論を再生成します。次に、最終的に正解に至ったすべての推論を微調整し、このプロセスを繰り返します。
OpenAI は、Strawberry のイノベーションによって AI モデルの推論能力が大幅に向上することを期待しています。これには特別な処理方法が必要です。AI モデルが大量のデータで事前トレーニングされた後、パフォーマンスが最適化されるように調整されます。
OpenAI はまた、Strawberry が長期タスク (LHT) を実行できるようにしたいと考えています。これには、モデルが一連のアクションを事前に計画して実行する必要があります。この目標を達成するために、彼らは「ディープリサーチ」データセットを作成して評価しています。
Strawberry プロジェクトの段階的な進歩により、OpenAI は AGI の目標の達成にますます近づいています。ストロベリーの推論能力が本当に人間に匹敵するものであれば、AIの未来は無限大となるでしょう。
OpenAI の「Strawberry」プロジェクトは間違いなく人工知能の分野における大きな進歩であり、その今後の発展には引き続き注目する価値があります。 Downcodes の編集者は今後もさらなるテクノロジー情報をお届けしていきますので、ご期待ください。