近年、人工知能は画像認識において大きな進歩を遂げてきましたが、ビデオの理解は依然として大きな課題です。ビデオ データのダイナミクスと複雑さは、AI に前例のない困難をもたらします。しかし、Google 研究チームが開発した VideoPrism ビデオ エンコーダは、この状況を変えることが期待されています。 Downcodes のエディターを使用すると、VideoPrism の強力な機能、トレーニング方法、および AI ビデオ理解の将来の分野への大きな影響について深く理解できます。
AI の世界では、機械が画像を理解することよりもビデオを理解することの方がはるかに困難です。ビデオはダイナミックで、サウンド、動き、複雑なシーンが多数含まれています。 AI が登場した以前は、ビデオを見るのは天国から本を読むようなもので、混乱することがよくありました。
しかし、VideoPrism の登場ですべてが変わるかもしれません。これは、Google 研究チームによって開発されたビデオ エンコーダで、さまざまなビデオ理解タスクを 1 つのモデルで最先端のレベルに到達できます。ビデオの分類、配置、字幕の生成、さらにはビデオに関する質問への回答も、VideoPrism で簡単に処理できます。

VideoPrismをトレーニングするにはどうすればよいですか?
VideoPrism をトレーニングするプロセスは、子供に世界の観察方法を教えるようなものです。まず、日常生活から科学観察まで、さまざまなビデオを表示する必要があります。次に、「高品質」のビデオと字幕のペアと、ノイズの多い並列テキスト (自動音声認識テキストなど) を使用してトレーニングも行います。
事前トレーニング方法
データ: VideoPrism は、3,600 万の高品質ビデオと字幕のペアと、ノイズの多い並列テキストを含む 5,820 万のビデオ クリップを使用します。
モデル アーキテクチャ: 標準ビジュアル トランスフォーマー (ViT) に基づいており、空間と時間の因数分解された設計を使用します。
トレーニング アルゴリズム: ビデオとテキストの比較トレーニングとマスクされたビデオ モデリングの 2 つの段階が含まれます。
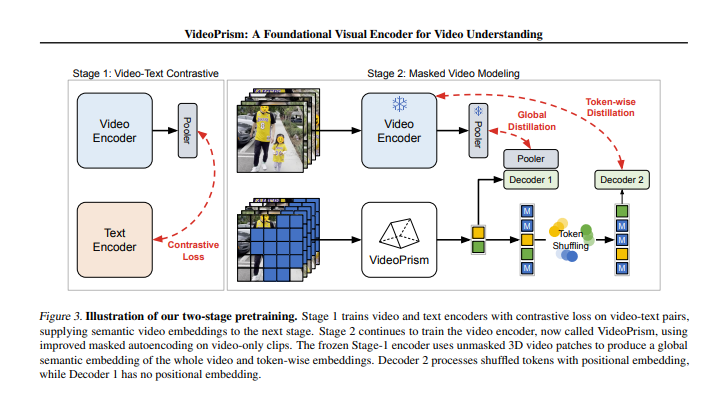
トレーニング プロセス中に、VideoPrism は 2 つの段階を経ます。最初の段階では、対比学習とグローバルとローカルの蒸留を通じてビデオとテキストの関係を学習します。第 2 段階では、マスクされたビデオ モデリングを通じてビデオ コンテンツの理解をさらに向上させます。
研究者らは複数のビデオ理解タスクで VideoPrism をテストし、その結果は印象的でした。 VideoPrism は、33 ベンチマーク中 30 で最先端のパフォーマンスを達成します。オンラインビデオの質問に答える場合でも、科学分野のコンピュータービジョンタスクに答える場合でも、VideoPrism は強力な機能を実証しています。
VideoPrism の誕生は、AI ビデオ理解の分野に新たな可能性をもたらしました。 AI がビデオ コンテンツをよりよく理解できるようになるだけでなく、教育、エンターテイメント、セキュリティ、その他の分野でも重要な役割を果たす可能性があります。
しかし、VideoPrism は、長いビデオを処理する方法や、トレーニング プロセス中にバイアスが入り込むのを回避する方法など、いくつかの課題にも直面しています。これらは将来の研究で対処する必要がある問題です。
論文アドレス: https://arxiv.org/pdf/2402.13217
全体として、VideoPrism の登場は、AI ビデオ理解の分野における大きな進歩を示しており、その強力なパフォーマンスと幅広い応用の可能性は刺激的です。 今後も技術の発展により、VideoPrismはより多くの分野でその価値を発揮し、人々の生活にさらなる利便性をもたらしていくと考えています。