最近、テンセント人工知能研究所は、ビデオ コンテンツを意味的および時間的に一貫したオーディオに効率的に変換するように設計された VTA-LDM と呼ばれる新しいモデルを発表しました。このモデルの中核となるテクノロジーは、生成されたオーディオおよびビデオ コンテンツを完全に一致させる「暗黙的アライメント」にあり、オーディオ生成の品質とアプリケーション シナリオを大幅に向上させます。 Downcodes のエディターは、VTA-LDM モデルの革新性とアプリケーションの見通しを深く理解するのに役立ちます。
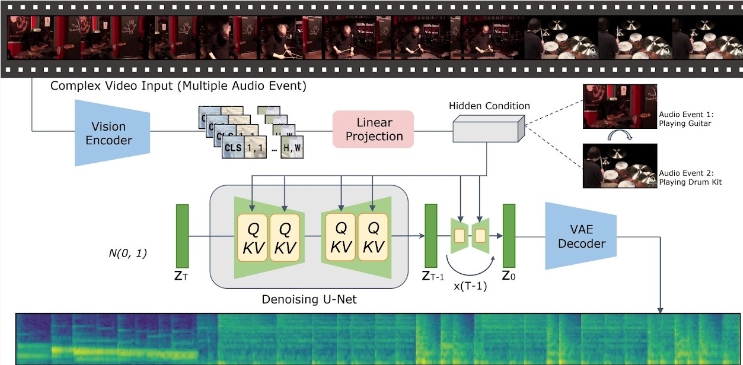
テキストからビデオへの生成技術の大幅な進歩に伴い、ビデオ入力から意味的および時間的に一貫したオーディオ コンテンツを生成する方法が研究者の間で話題になっています。最近、Tencent Artificial Intelligence Laboratory の研究チームは、効率的なオーディオ生成ソリューションを提供することを目的とした、「Implicitly Aligned Video to Audio Generation」(暗黙的に整列されたビデオとオーディオの生成) - VTA-LDM と呼ばれる新しいモデルを発表しました。
プロジェクト入口: https://top.aibase.com/tool/vta-ldm
VTA-LDM モデルの中心となるアイデアは、暗黙的なアライメント テクノロジを通じて、生成されたオーディオおよびビデオ コンテンツを意味的および時間的に一致させることです。この方法は、オーディオ生成の品質を向上させるだけでなく、ビデオ生成テクノロジーの応用シナリオも拡張します。研究チームはモデル設計について徹底的な調査を実施し、生成されるオーディオの精度と一貫性を確保するためにさまざまな技術的手段を組み合わせました。
この研究は、ビジュアル エンコーダ、補助埋め込み、データ拡張技術という 3 つの重要な側面に焦点を当てています。研究チームはまず基本モデルを確立し、これに基づいて多数のアブレーション実験を実施して、さまざまな視覚エンコーダと補助埋め込みが生成効果に及ぼす影響を評価しました。これらの実験の結果は、このモデルが生成品質とビデオとオーディオの同時調整の点で優れたパフォーマンスを示し、現在のテクノロジーの最前線に達していることを示しています。
推論に関しては、ユーザーは指定されたデータ ディレクトリにビデオ クリップを配置し、提供された推論スクリプトを実行して対応するオーディオ コンテンツを生成するだけで済みます。研究チームは、ユーザーが生成された音声を元のビデオと結合して、アプリケーションの利便性をさらに向上させるための一連のツールも提供しています。
VTA-LDM モデルは現在、さまざまな研究ニーズを満たすために複数の異なるモデル バージョンを提供しています。これらのモデルは、基本モデルとさまざまな拡張モデルをカバーしており、さまざまな実験やアプリケーションのシナリオに適応する柔軟な選択肢をユーザーに提供することを目的としています。
VTA-LDM モデルの発表は、ビデオからオーディオへの生成の分野における重要な進歩を示しており、研究者らはこのモデルを使用して関連技術の開発を促進し、より豊かなアプリケーションの可能性を創出したいと考えています。
## ハイライト:
VTA-LDM モデルの登場は、ビデオおよびオーディオ生成の分野に新たなブレークスルーをもたらし、その効率的で便利な操作方法と強力な機能により、将来の幅広いアプリケーションの可能性が広がります。技術の継続的な発展により、VTA-LDM モデルはより多くの分野で重要な役割を果たすと考えられています。