ダウンコードエディターが大きなニュースをもたらします!革新的な Transformer アクセラレーション テクノロジー FlashAttendant-3 が正式リリースされました。このテクノロジーは、大規模言語モデル (LLM) の推論速度とコストに革命をもたらし、前例のない効率の向上を実現します。 1.5~2倍の高速化、低精度(FP8)演算でも高精度を維持、長文処理能力が大幅に強化され、AIアプリケーションに新たな可能性をもたらします!この画期的なテクノロジーを詳しく見てみましょう。
新しい Transformer アクセラレーション テクノロジ FlashAttendant-3 がリリースされました。これは単なるアップグレードではなく、推論速度の大幅な向上と大規模言語モデル (LLM) のコストの大幅な削減を予告します。
まずこの FlashAttendant-3 について説明します。以前のバージョンと比較すると、単なるショットガンの変更です。
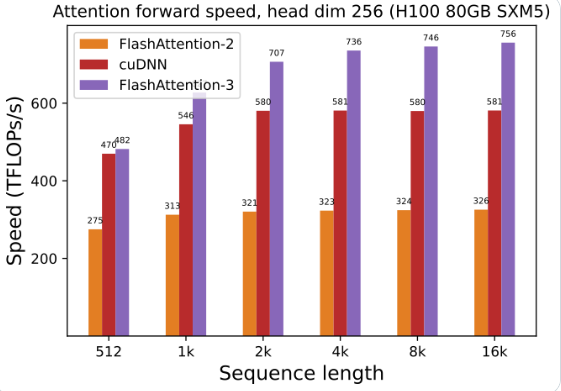
GPU の使用率が大幅に向上しました。FlashAttendant-3 を使用して大規模な言語モデルをトレーニングおよび実行すると、速度が直接 2 倍になり、1.5 ~ 2 倍高速になりました。この効率は驚くべきものです。
低精度、高パフォーマンス: 精度を維持しながら、低精度の数値 (FP8) でも実行できます。これはどういう意味ですか?
長いテキストの処理は簡単です。FlashAttendant-3 は、以前は想像できなかった長いテキストを処理する AI モデルの能力を大幅に強化します。
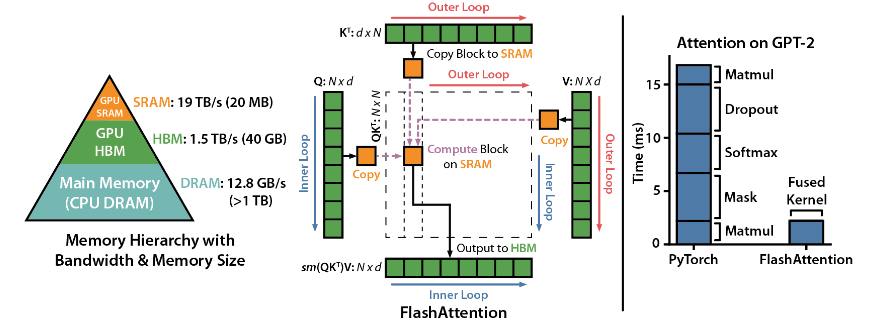
FlashAttention は、Dao-AILab によって開発されたオープン ソース ライブラリであり、2 つの重要な論文に基づいており、ディープ ラーニング モデルにおけるアテンション メカニズムの最適化された実装を提供します。このライブラリは、大規模なデータ セットや長いシーケンスの処理に特に適しています。メモリ消費量とシーケンスの長さの間には線形の関係があり、従来の 2 次の関係よりもはるかに効率的です。
技術的なハイライト:
高度なテクノロジーのサポート: ローカル アテンション、決定論的バックプロパゲーション、ALiBi など。これらのテクノロジーは、モデルの表現力と柔軟性をより高いレベルにもたらします。
Hopper GPU の最適化: FlashAttendant-3 は、Hopper GPU のサポートを特別に最適化し、パフォーマンスが 1.5 ポイント以上向上しました。
インストールと使用が簡単: CUDA11.6 および PyTorch1.12 以降をサポートし、Linux システムでは pip コマンドで簡単にインストールできます。Windows ユーザーにはさらにテストが必要かもしれませんが、試してみる価値は間違いなくあります。
コア機能:
効率的なパフォーマンス: 最適化されたアルゴリズムにより、特に長いシーケンスのデータ処理の場合に、コンピューティングとメモリの要件が大幅に軽減され、パフォーマンスの向上が目に見えてわかります。
メモリの最適化: 従来の方法と比較して、FlashAttendant はメモリ消費量が少なく、線形関係によりメモリ使用量が問題になりません。
高度な機能: さまざまな高度なテクノロジーを統合することで、モデルのパフォーマンスとアプリケーションの範囲が大幅に向上します。
使いやすさと互換性: シンプルなインストールと使用ガイドと複数の GPU アーキテクチャのサポートにより、FlashAttendant-3 をさまざまなプロジェクトに迅速に統合できます。
プロジェクトアドレス: https://github.com/Dao-AILab/flash-attention
FlashAttendant-3 の登場により、大規模言語モデルの応用と開発が加速し、人工知能の分野に新たなブレークスルーがもたらされることは間違いありません。 その効率的なパフォーマンスと使いやすさにより、開発者にとって理想的な選択肢となります。 急いで体験してください!