Downcodes の編集者は、Google DeepMind による画期的な研究、Mixture of Experts (MoE) について学ぶことができます。この研究は、Transformer アーキテクチャに革命的な進歩をもたらしました。その核心は、プロダクト キー テクノロジを使用して計算コストとパラメータ数のバランスをとり、効率を維持しながらモデルの可能性を大幅に向上させる、パラメータ効率の高いエキスパート検索メカニズムにあります。この研究は、極端な MoE 設定を調査するだけでなく、学習インデックス構造を 100 万人以上の専門家に効果的にルーティングできることを初めて証明し、AI 分野に新たな可能性をもたらします。
Google DeepMind によって提案された 100 万人の専門家による混合モデルは、Transformer アーキテクチャにおいて革命的な一歩を踏み出した研究です。
100 万人のマイクロ専門家からのスパース検索を実行できるモデルを想像してみてください。これは SF 小説のプロットのように聞こえますか? しかし、それがまさに DeepMind の最新の研究によって示されています。この研究の中核となるのは、プロダクト キー テクノロジを利用して計算コストをパラメータ数から切り離す、パラメータ効率の高いエキスパート検索メカニズムです。これにより、計算効率を維持しながら、Transformer アーキテクチャのより大きな可能性が解放されます。
この研究のハイライトは、極端な MoE 設定を調査するだけでなく、学習されたインデックス構造が 100 万人を超える専門家に効率的にルーティングできることを初めて実証したことです。これは、大勢の群衆の中から問題を解決できる少数の専門家を素早く見つけるようなもので、これらすべては制御可能なコンピューティング コストを前提として行われます。
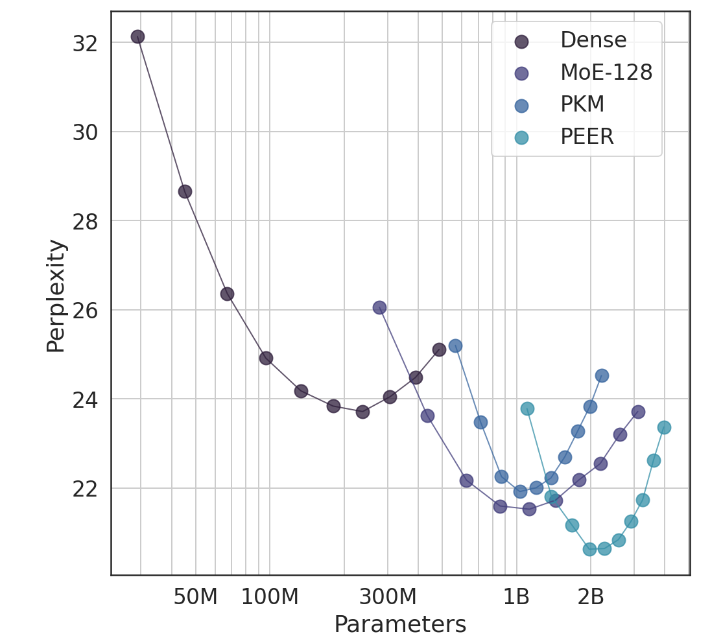
実験では、PEER アーキテクチャは優れたコンピューティング パフォーマンスを実証し、高密度 FFW、粗粒 MoE、およびプロダクト キー メモリ (PKM) レイヤーよりも効率的でした。これは理論上の勝利であるだけでなく、実際の応用においても大きな進歩です。経験的な結果から、エキスパートの数とアクティブなエキスパートの数を調整することで、言語モデリング タスクにおける PEER のパフォーマンスが優れていることがわかります。また、アブレーション実験においても PEER のパフォーマンスが向上します。モデルは大幅に改良されました。
この研究の著者である Xu He (Owen) は、Google DeepMind の研究科学者です。彼の独力での探究は間違いなく AI の分野に新たな発見をもたらしました。彼が示したように、パーソナライズされたインテリジェントな方法を通じて、コンバージョン率を大幅に向上させ、ユーザーを維持することができます。これは AIGC 分野で特に重要です。
論文アドレス: https://arxiv.org/abs/2407.04153
全体として、Google DeepMind の 100 万人の専門家によるハイブリッド モデルの研究は、大規模な言語モデルの構築に新しいアイデアを提供し、その効率的な専門家検索メカニズムと優れた実験結果は、将来の AI モデル開発に大きな可能性を示しています。 Downcodes の編集者は、同様の画期的な研究結果をさらに楽しみにしています。