人工知能のトレーニングには時間がかかり、コンピューティング能力を消費します。これが常に AI 分野のボトルネックとなっています。 DeepMind チームは最近画期的な研究を発表し、この問題を効果的に解決する JEST と呼ばれる新しいデータ スクリーニング方法を提案しました。 Downcodes のエディターは、JEST が AI トレーニングの効率を大幅に向上させる方法を深く理解し、その背後にある技術原則を説明します。
人工知能の分野では、コンピューティング能力と時間が常に技術の進歩を制限する重要な要因となってきました。ただし、DeepMind チームの最新の研究結果は、この問題に対する解決策を提供します。
彼らは、JEST と呼ばれる新しいデータ スクリーニング手法を提案しました。これは、トレーニングに最適なデータ バッチをインテリジェントにスクリーニングすることで、AI のトレーニング時間と計算能力要件の大幅な削減を実現します。 AIのトレーニング時間を13分の1に短縮し、必要な計算能力を90%削減できるという。
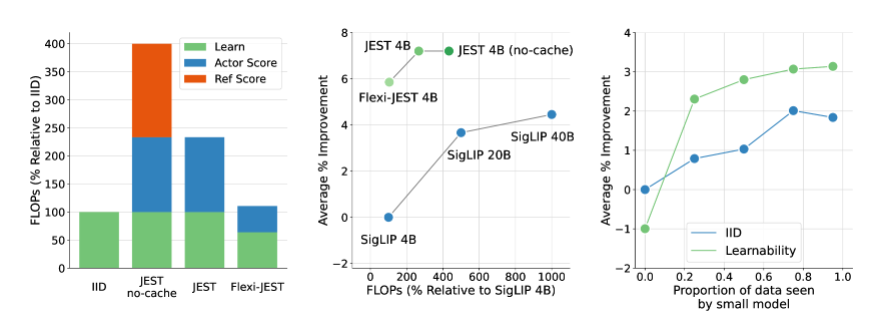
JEST メソッドの中核は、個々のサンプルではなくデータの最適なバッチを共同で選択することにあり、これはマルチモーダル学習の加速に特に効果的であることが証明されている戦略です。従来の大規模な事前トレーニング データ スクリーニング方法と比較して、JEST は反復と浮動小数点演算の数を大幅に削減するだけでなく、FLOP 予算のわずか 10% を使用しながら以前の最先端技術を上回ります。
DeepMind チームの調査により、3 つの重要なポイントが明らかになりました。データ ポイントを個別に選択するよりも、適切なデータ バッチを選択する方が効果的であること、オンライン モデル近似を使用してデータをより効率的にフィルタリングできること、小規模で高品質なデータ セットをブートストラップして大規模なデータ セットを活用できることです。 . キュレーションされていないデータセット。これらの発見は、JEST メソッドの効率的なパフォーマンスの理論的基礎を提供します。
JEST の動作原理は、RHO 損失に関する以前の研究を利用し、学習モデルの損失と事前トレーニングされた参照モデルを組み合わせることによって、データ ポイントの学習可能性を評価することです。トレーニングの効率と有効性を向上させるために、事前トレーニングされたモデルにとっては容易であるが、現在の学習モデルにとってはより困難なデータ ポイントが選択されます。
さらに、JEST は、ブロッキング ギブズ サンプリングに基づいた反復手法を採用して、徐々にバッチを構築し、各反復の条件付き学習可能性スコアに基づいて新しいサンプル サブセットを選択します。このアプローチは、データをスコアリングするために事前トレーニングされた参照モデルのみを使用するなど、より多くのデータがフィルターされるにつれて改善され続けています。
DeepMind によるこの研究は、AI トレーニングの分野に画期的な進歩をもたらすだけでなく、将来の AI 技術開発に新しいアイデアと手法を提供します。 JEST 手法のさらなる最適化と応用により、人工知能の発展によりより広い展望がもたらされると信じる理由があります。
論文: https://arxiv.org/abs/2406.17711
ハイライト:
**トレーニング効率革命**: DeepMind の JEST メソッドは、AI トレーニング時間を 13 分の 1 に短縮し、必要な計算能力を 90% 削減します。
**データ バッチ スクリーニング**: JEST は、個々のサンプルではなく最適なデータ バッチを共同で選択することにより、マルチモーダル学習の効率を大幅に向上させます。
?️ **革新的なトレーニング方法**: JEST は、オンライン モデル近似と高品質のデータセット ガイダンスを利用して、大規模な事前トレーニングのデータ分散とモデル一般化機能を最適化します。
JEST手法の登場はAIトレーニングに新たな希望をもたらし、その効率的なデータスクリーニング戦略により、さまざまな分野でのAI技術の応用と発展が促進されることが期待されています。将来的には、より実用的なアプリケーションで JEST がパフォーマンスを発揮し、人工知能の分野でのブレークスルーがさらに促進されることを楽しみにしています。 Downcodes の編集者は今後も関連する動向に注目し、読者にさらにエキサイティングなレポートをお届けしていきます。