Downcodes の編集者は、Groq が最近、業界の期待をはるかに上回る処理速度を実現し、開発者に前例のない大規模な言語モデルのインタラクティブなエクスペリエンスを提供する素晴らしい LLM エンジンをリリースしたことを知りました。このエンジンは Meta のオープン ソース LLama3-8b-8192LLM をベースにしており、他のモデルもサポートしています。その処理速度は 1 秒あたり 1256.54 マークと高く、Nvidia などの企業の GPU チップを大幅に上回っています。この画期的な開発は、開発者から広く注目を集めただけでなく、より高速で柔軟な LLM アプリケーション エクスペリエンスを一般ユーザーにもたらしました。
Groq は最近、自社 Web サイト上で超高速 LLM エンジンをリリースしました。これにより、開発者は大規模な言語モデルで高速なクエリとタスクの実行を直接実行できるようになります。
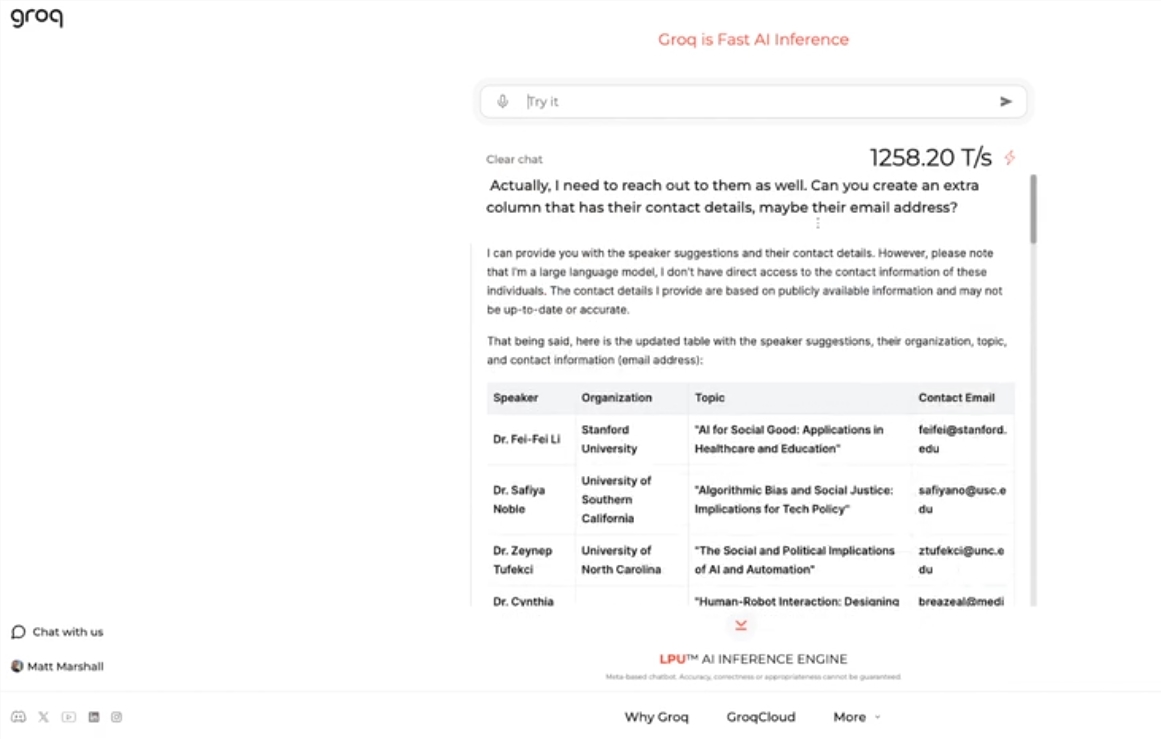
このエンジンは Meta のオープン ソース LLama3-8b-8192LLM を使用し、デフォルトで他のモデルをサポートし、驚くほど高速です。テスト結果によると、Groq のエンジンは 1 秒あたり 1256.54 マークを処理でき、Nvidia などの企業の GPU チップをはるかに上回っています。この動きは開発者と非開発者を問わず広く注目を集め、LLM チャットボットのスピードと柔軟性を実証しました。
Groq CEO の Jonathan Ross 氏は、Groq の高速エンジンで LLM を使用することがどれほど簡単かを人々が理解するにつれて、LLM の使用はさらに増加すると述べました。デモを通じて、求人広告の作成や記事内容の修正など、さまざまな作業がこの速度で簡単に完了できることがわかります。 Groq のエンジンは音声コマンドに基づいてクエリを実行することもでき、そのパワーと使いやすさを実証しています。
無料の LLM ワークロード サービスの提供に加え、Groq は開発者に OpenAI 上に構築されたアプリケーションを Groq に簡単に切り替えることができるコンソールも提供します。
このシンプルな切り替え方法が多くの開発者を魅了し、現在 28 万人以上が Groq のサービスを利用しています。ロス最高経営責任者(CEO)は、来年までに世界の推論計算の半分以上がGroqのチップ上で実行されるようになり、AI分野における同社の可能性と展望を実証すると述べた。
ハイライト:
Groq は、GPU 速度をはるかに上回る 1 秒あたり 1256.54 マークを処理する超高速 LLM エンジンを起動します
Groq のエンジンは LLM チャットボットの速度と柔軟性を実証し、開発者と非開発者の両方の注目を集めています
Groq は、280,000 人以上の開発者によって使用されている無料の LLM ワークロード サービスを提供しています。来年には世界の推論計算の半分が同社のチップで実行されると予想されています。
Groq の高速 LLM エンジンは間違いなく AI 分野に新たな可能性をもたらし、その高いパフォーマンスと使いやすさは LLM テクノロジーの幅広い応用を促進するでしょう。 Downcodes 編集者は、Groq の今後の発展に期待する価値があると信じています。