Downcodes の編集者がビッグニュースをお届けします! Cerebras Systems は、世界最速の AI 推論サービス - Cerebras Inference を開始しました。これは、驚くべきスピードと非常に競争力のある価格で、AI 推論の分野におけるゲームのルールを完全に変えました。さまざまな AI モデル、特に大規模言語モデル (LLM) の処理に優れたパフォーマンスを発揮し、従来の GPU システムよりも 20 倍高速でありながら、10 分の 1、さらには 100 分の 1 という低価格を実現します。これは今後の AI アプリケーションの開発にどのような影響を与えるのでしょうか?詳しく見てみましょう。
パフォーマンス AI コンピューティングのパイオニアである Cerebras Systems は、AI 推論に革命をもたらす画期的なソリューションを導入しました。 2024 年 8 月 27 日、同社は世界最速の AI 推論サービスである Cerebras Inference の開始を発表しました。 Cerebras Inference のパフォーマンス指標は従来の GPU ベースのシステムをはるかに下回り、極めて低コストで 20 倍の速度を提供し、AI コンピューティングの新たなベンチマークを設定します。
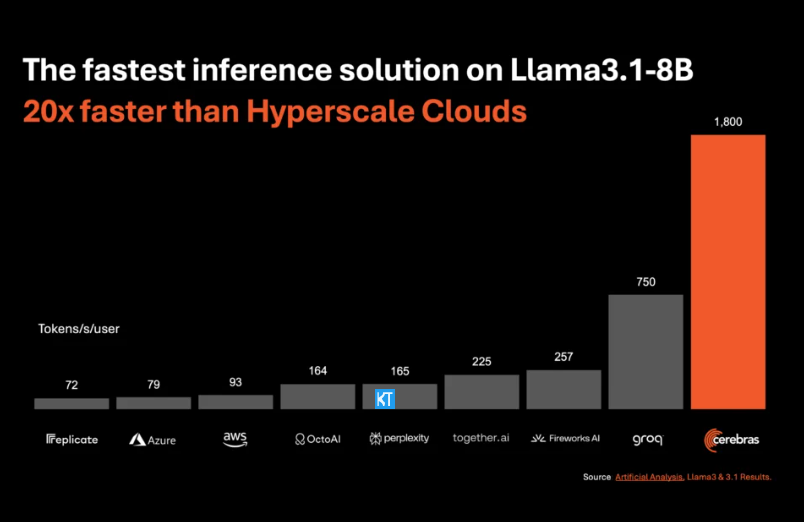
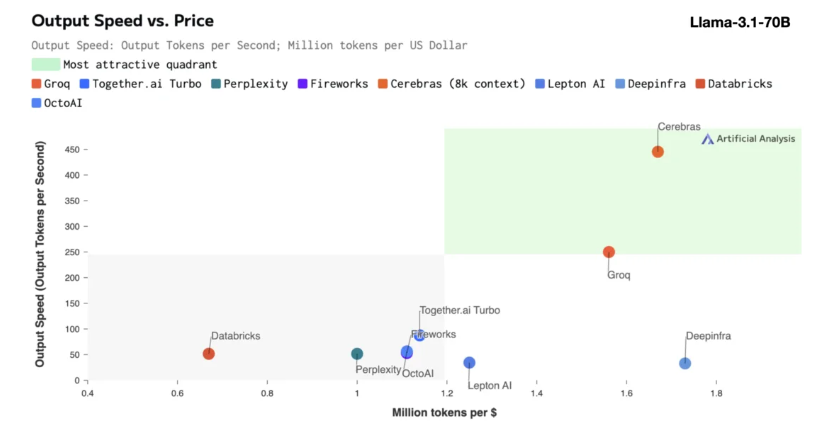
Cerebras 推論は、さまざまなタイプの AI モデル、特に急速に発展している「大規模言語モデル」(LLM) の処理に特に適しています。最新の Llama3.1 モデルを例に挙げると、その 8B バージョンは 1 秒あたり 1,800 トークンを処理でき、70B バージョンは 450 トークンを処理できます。これは、NVIDIA GPU ソリューションより 20 倍高速であるだけでなく、価格も競争力があります。 Cerebras Inference の価格は 100 万トークンあたりわずか 10 セントから始まり、70B バージョンは 60 セントです。既存の GPU 製品と比較して、価格性能比は 100 倍向上しています。
Cerebras Inference が業界トップの精度を維持しながらこの速度を達成していることは印象的です。他の速度優先のソリューションとは異なり、Cerebras は常に 16 ビット ドメインで推論を実行し、パフォーマンスの向上が AI モデルの出力品質を犠牲にしないようにします。 Artificial Analytics の CEO、Micha Hill-Smith 氏は、Cerebras が Meta の Llama3.1 モデルで 1 秒あたり 1,800 個を超える出力トークンの速度を達成し、新記録を樹立したと述べました。
AI 推論は AI コンピューティングの中で最も急速に成長している分野であり、AI ハードウェア市場全体の約 40% を占めています。 Cerebras が提供するような高速 AI 推論は、ブロードバンド インターネットの出現に似ており、新たな機会を切り開き、AI アプリケーションの新時代の到来をもたらします。開発者は Cerebras Inference を使用して、インテリジェント エージェントやインテリジェント システムなど、複雑なリアルタイム パフォーマンスを必要とする次世代 AI アプリケーションを構築できます。
Cerebras Inference は、無料層、開発者層、エンタープライズ層の 3 つの手頃な価格のサービス層を提供します。無料利用枠では、寛大な使用制限付きの API アクセスが提供されるため、幅広いユーザーにとって理想的です。開発者層は柔軟なサーバーレス展開オプションを提供し、エンタープライズ層は継続的なワークロードを持つ組織にカスタマイズされたサービスとサポートを提供します。
コアテクノロジーに関しては、Cerebras Inference は業界をリードする Wafer Scale Engine3 (WSE-3) によって駆動される CerebrasCS-3 システムを使用しています。この AI プロセッサは規模と速度において比類のないもので、NVIDIA H100 の 7,000 倍のメモリ帯域幅を提供します。
Cerebras Systems は、AI コンピューティング分野のトレンドをリードするだけでなく、医療、エネルギー、政府、科学技術コンピューティング、金融サービスなどの複数の業界で重要な役割を果たしています。 Cerebras は、技術革新を継続的に進めることで、さまざまな分野の組織が AI の複雑な課題に対処できるよう支援しています。
ハイライト:
Cerebras Systems のサービス速度は 20 倍に向上し、価格競争力が高まり、AI 推論の新時代が開かれます。
さまざまな AI モデルをサポートし、特に大規模言語モデル (LLM) で優れたパフォーマンスを発揮します。
開発者や企業ユーザーが柔軟に選択できるよう、3 つのサービス レベルが提供されています。
全体として、Cerebras Inference の登場は、AI 推論の分野における重要なマイルストーンであり、その優れたパフォーマンスと経済性により、AI アプリケーションの広範な普及と革新的な開発が促進され、業界の注目と期待に値します。 Downcodes の編集者は、今後も最先端のテクノロジー情報をお届けしていきます。