人工知能の分野では、音声認識技術は常に注目の研究テーマです。今日、ByteDance が発表した Seed-ASR エンジンは、その強力なパフォーマンスと幅広い言語サポートにより、音声認識テクノロジーに新たなブレークスルーをもたらしました。 Seed-ASRの素晴らしさをDowncodes編集者が詳しく解説します。
音声認識技術は、常に人工知能の開発における重要な分野の 1 つです。現在、ByteDance が発表した Seed-ASR エンジンは、言語と方言の壁を完全に打ち破り、このテクノロジーに新たな活力を注入しています。
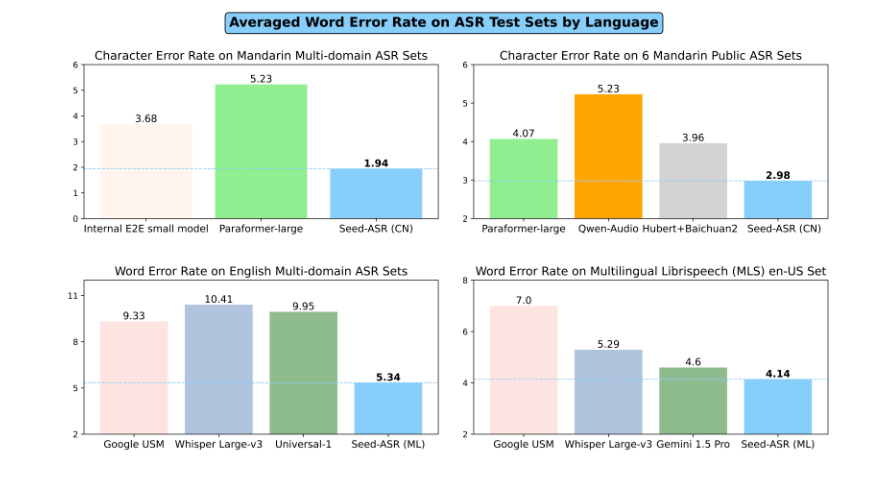
Seed-ASR は、2,000 万時間以上の音声データとほぼ 90 万時間のペア データでトレーニングされており、優れた認識機能を実証しています。中国語を正確に認識できるだけでなく、13 の中国の方言と、さまざまなアクセントの英語を含む 7 つの外国語を正確に書き写すことができます。これは間違いなく、言語を超えたコミュニケーションに新たな可能性をもたらします。
Seed-ASR の主な利点は、その優れたコンテキスト認識です。過去の会話記録、会議議事録、その他の情報を組み合わせて、人名、地名、キーワードをより正確に特定できます。これにより、特定のシナリオで特に優れたパフォーマンスが得られ、認識精度が大幅に向上します。
簡単な日常会話でも、複雑な会議コミュニケーションでも、Seed-ASR は簡単に処理できます。複数の人が話している場合や周囲の騒音がある場合でも、コンテンツを正確に文字に起こすことができます。ビデオや生の音声を処理する際にも、さまざまな音質や環境に適応できます。
Seed-ASR は、医療、テクノロジー、自動車、さらには音楽など、さまざまな専門分野の用語も認識できます。これにより、スマート アシスタントや音声検索のシナリオで威力を発揮し、ユーザー エクスペリエンスが大幅に向上します。
プロジェクトアドレス: https://bytedancespeech.github.io/seedasr_tech_report/
Seed-ASR の登場は、音声認識テクノロジーの新たな高みを示すものであり、その強力な機能と幅広い応用の可能性が期待されます。 Downcodes の編集者は、将来の人工知能の開発において Seed-ASR がますます重要な役割を果たすようになるだろうと信じています。