近年、人工知能技術の急速な発展は、大量のデータのトレーニングに大きく依存しています。しかし、Downcodes の編集者は、MIT およびその他の機関による最新の研究で、データ入手の難しさが劇的に増加していることを指摘していることを発見しました。かつては簡単に利用できたネットワーク データは現在、ますます厳しく制限されており、AI のトレーニングと開発に大きな課題をもたらしています。複数のオープンソース データセットを分析したこの研究では、この厳しい現実が明らかになりました。
人工知能の急速な発展の裏で、データ取得の難しさという深刻な問題が表面化しています。 MIT およびその他の機関による最新の研究によると、かつては簡単にアクセスできた Web データにアクセスすることがますます困難になっており、これが AI のトレーニングと研究に大きな課題をもたらしていることがわかりました。
研究者らは、C4、RefineWeb、Dolma などの複数のオープンソース データセットによってクロールされる Web サイトがライセンス契約を急速に強化していることを発見しました。これは商用 AI モデルのトレーニングに影響を与えるだけでなく、学術機関や非営利団体による研究にも影響を及ぼします。

この調査は、MITメディアラボ、ウェルズリー大学、AIスタートアップのRaiveなどのチームリーダー4人によって実施された。彼らは、データ制限が急増し、ライセンスの非対称性と不一致がますます明らかになっていると指摘しています。
研究チームは、調査方法としてロボット排除プロトコル (REP) と Web サイトの利用規約 (ToS) を使用しました。彼らは、OpenAI のような大手 AI 企業のクローラーですら、ますます厳しい制限に直面していることを発見しました。
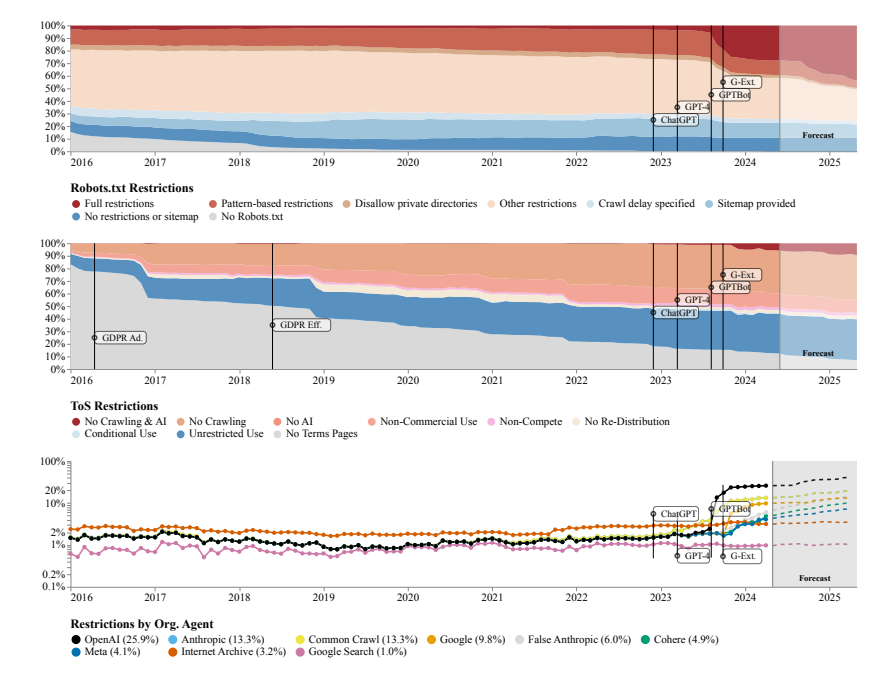
SARIMA モデルは、robots.txt または ToS を通じて、Web サイトのデータ制限は将来的に増加し続けると予測しています。これは、オープン ネットワーク データへのアクセスがより困難になることを示唆しています。
この調査では、インターネットからクロールされたデータが AI モデルのトレーニング目的と一致しておらず、モデルの調整、データ収集の慣行、および著作権に影響を与える可能性があることも判明しました。
研究チームは、ウェブサイト所有者の希望を反映し、許可されるユースケースと許可されないユースケースを分離し、利用規約と同期させる、より柔軟な契約の必要性を訴えています。同時に彼らは、AI開発者がトレーニングのためにオープンウェブ上のデータを使用できるようにしたいと考えており、将来の法律がこれをサポートすることを望んでいます。
論文のアドレス: https://www.dataprovenance.org/Consent_in_Crisis.pdf
この研究は、人工知能分野におけるデータ取得の問題に警鐘を鳴らし、将来の AI モデルのトレーニングと開発に対する新たな課題も提起しました。データ取得とウェブサイト所有者の権利と利益のバランスをどう取るかは、人工知能の分野で真剣に検討し、解決する必要がある重要な問題となるでしょう。 Downcodes の編集者は、詳細を知るためにこの論文に注目することをお勧めします。