大規模言語モデル (LLM) トレーニングでは、チェックポイント メカニズムはトレーニングの中断によって引き起こされる大きな損失を効果的に回避できるため、非常に重要です。ただし、従来のチェックポイント システムは I/O ボトルネックに直面することが多く、非効率的です。この目的を達成するために、ByteDance と香港大学の科学者は、LLM トレーニングの効率を大幅に向上させる ByteCheckpoint と呼ばれる新しいチェックポイント システムを提案しました。
データとアルゴリズムが支配するデジタル世界では、人工知能の成長のあらゆる段階は、重要な要素であるチェックポイントから切り離すことができません。人々の心を理解し、質問に流暢に答えることができる大規模な言語モデルをトレーニングしているとき、このモデルは非常に賢いですが、大食漢でもあり、それを養うために大量のコンピューティング リソースを必要とすることを想像してください。トレーニング中に突然の停電やハードウェア障害が発生した場合、損失は甚大になります。このとき、チェックポイントはタイムマシンのようなもので、すべてが以前の安全な状態に戻り、未完了のタスクを続行できるようになります。
ただし、タイムマシン自体も慎重な設計が必要でした。 ByteDance と香港大学の科学者は、論文「ByteCheckpoint: LLM 開発のための統合チェックポイント システム」で新しいチェックポイント システム ByteCheckpoint を紹介しました。これは単純なバックアップ ツールであるだけでなく、大規模な言語モデルのトレーニング効率を大幅に向上させる成果物でもあります。
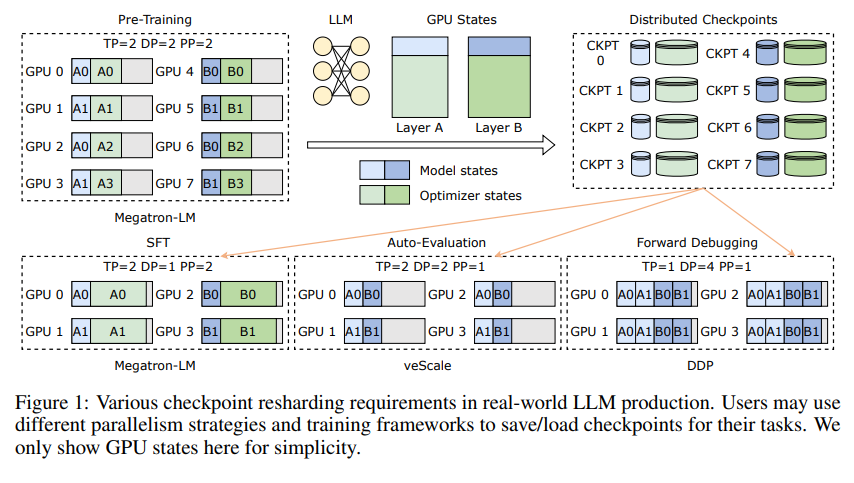
まず、大規模言語モデル (LLM) が直面する課題を理解する必要があります。これらのモデルが大きい理由は、大量の情報を処理して記憶する必要があるためであり、そのため、トレーニング コストが高くつく、リソースを大量に消費する、フォールト トレランスが弱いなどの問題が発生します。一度故障が発生すると、長期間のトレーニングが満足に行えなくなる可能性があります。
チェックポイント システムはモデルのスナップショットのようなもので、トレーニング プロセス中に状態を定期的に保存するため、何か問題が発生してもすぐに最新の状態に復元でき、損失を軽減できます。ただし、既存のチェックポイント システムは、大規模なモデルを処理する際の I/O (入出力) ボトルネックによる非効率性に悩まされることがよくあります。
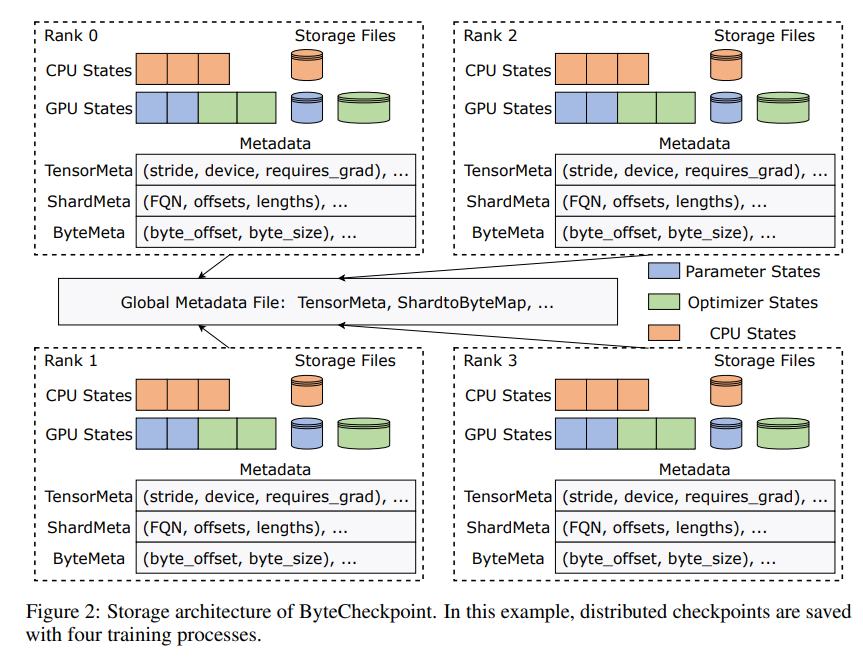
ByteCheckpoint の革新性は、データとメタデータを分離し、さまざまな並列構成とトレーニング フレームワークの下でチェックポイントをより柔軟に処理する新しいストレージ アーキテクチャの採用にあります。さらに良いことに、オンライン チェックポイントの自動リシャーディングがサポートされており、トレーニングを中断することなく、チェックポイントを動的に調整してさまざまなハードウェア環境に適応できます。
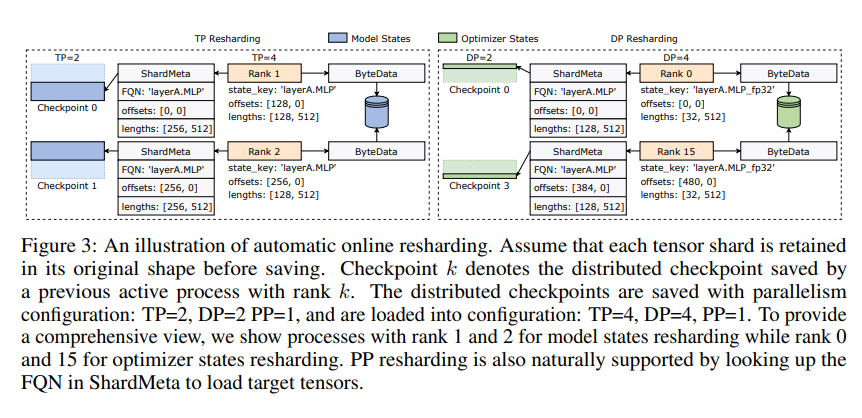
ByteCheckpoint では、非同期テンソル マージという重要なテクノロジも導入しています。これにより、異なる GPU に不均等に分散されたテンソルを効率的に処理でき、チェックポイントが再シャーディングされたときにモデルの整合性と一貫性が影響を受けないことが保証されます。
チェックポイントの保存とロードの速度を向上させるために、ByteCheckpoint は、高度な保存/ロード パイプライン、ピンポン メモリ プール、ワークロード バランスのとれた保存、ゼロ冗長ロードなどの一連の I/O パフォーマンス最適化手段も統合しています。トレーニングプロセス中の待ち時間を大幅に短縮します。
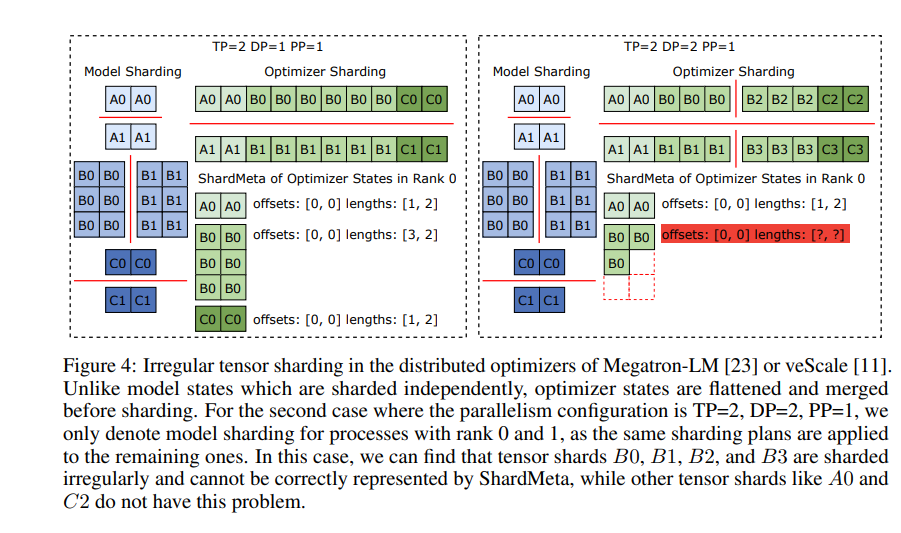
実験的な検証により、従来の方法と比較して、ByteCheckpoint のチェックポイントの保存速度と読み込み速度がそれぞれ数十倍、さらには数百倍も向上し、大規模な言語モデルのトレーニング効率が大幅に向上しました。
ByteCheckpoint はチェックポイント システムであるだけでなく、大規模な言語モデルのトレーニング プロセスにおける強力なアシスタントでもあり、より効率的で安定した AI トレーニングの鍵となります。
論文アドレス: https://arxiv.org/pdf/2407.20143
Downcodes の編集者は次のように要約しています: ByteCheckpoint の登場は、LLM トレーニングにおけるチェックポイント効率の低さの問題を解決し、AI 開発に強力な技術サポートを提供することに注目する価値があります。