自然言語処理 (NLP) の分野は日々変化しており、大規模言語モデル (LLM) の急速な開発は、前例のない機会と課題を私たちにもたらしています。中でも、モデルの評価が人間による注釈付きデータに依存していることがボトルネックとなっており、データ収集作業にコストと時間がかかるため、モデルの効果的な評価と継続的な改善が制限されています。 Downcodes の編集者は、この問題を解決するための新しいアイデアを提供する、Meta FAIR 研究者によって提案された新しいソリューション、「自己学習評価器」を紹介します。
今日の時代では、自然言語処理 (NLP) の分野が急速に発展しており、大規模言語モデル (LLM) は複雑な言語関連のタスクを高精度で実行できるため、人間とコンピューターの対話にさらなる可能性をもたらしています。ただし、NLP の重大な問題は、モデルの評価が人による注釈に依存していることです。
人間が生成したデータはモデルのトレーニングと検証にとって重要ですが、このデータの収集には費用と時間がかかります。さらに、モデルが改良され続けると、以前に収集されたアノテーションを更新する必要がある場合があり、その結果、新しいデータを継続的に取得する必要が生じ、効果的なモデル評価の規模と持続可能性に課題が生じます。
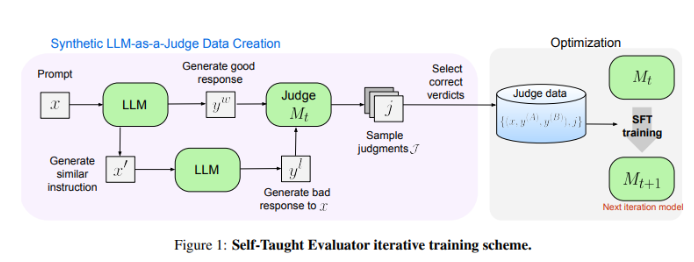
Meta FAIR の研究者は、「独習評価者」という新しいソリューションを考案しました。このアプローチは人間による注釈を必要とせず、合成的に生成されたデータに基づいてトレーニングされます。まず、シード モデルが対照的な合成プリファレンス ペアを生成し、次にモデルがこれらのペアを評価し、独自の判断を使用してそれらのペアを繰り返し改善し、後続の繰り返しでのパフォーマンスを向上させます。これにより、人間が生成したアノテーションへの依存が大幅に削減されます。
研究者らは、Llama-3-70B-Instruct モデルを使用して「自己学習評価器」のパフォーマンスをテストしました。この方法により、RewardBench ベンチマークでのモデルの精度が 75.4 から 88.7 に向上し、人間によるアノテーションでトレーニングされたモデルのパフォーマンスと同等、またはそれを超えています。複数回の反復の後、最終モデルは 1 回の推論で 88.3、多数決で 88.7 の精度を達成し、その強力な安定性と信頼性を実証しました。
「Self-Learning Evaluator」は、合成データと反復的な自己改善を活用して、NLP モデル評価のためのスケーラブルで効率的なソリューションを提供し、人間の注釈に依存して言語モデルの開発を進めるという課題に対処します。
論文アドレス: https://arxiv.org/abs/2408.02666
Meta FAIR の「自己学習評価ツール」は、NLP モデルの評価に革命的な変化をもたらし、その効率的でスケーラブルな機能は、将来の言語モデルの継続的な進歩を効果的に促進します。 この研究結果は、人間が注釈を付けたデータへの依存を減らすだけでなく、より重要なことに、より強力で信頼性の高い NLP モデルを構築する道を開くものです。 今後も同様のイノベーションがさらに増えることを楽しみにしています。