メタカンパニー大放出!オープンソースの最新の大規模言語モデル Llama 3.1 405B は、パラメータ量が最大 1,280 億で、そのパフォーマンスは複数のタスクにおいて GPT-4 に匹敵します。プロジェクト計画から最終レビューまで、1 年間の慎重な準備を経て、Llama 3 シリーズ モデルがついに一般公開されることになりました。このオープンソースには、モデル自体だけでなく、その最適化されたトレーニング前のデータ処理、トレーニング後のデータ品質保証、コンピューティング要件を軽減し、開発者が使いやすくする効率的な定量化テクノロジーも含まれています。 Downcodes編集者がLlama 3.1 405Bの改良点やハイライトを詳しく解説します。
昨夜、Meta は最新の大規模言語モデル Llama3.1 405B のオープンソースを発表しました。このビッグニュースは、プロジェクト計画から最終レビューまで、1 年間の慎重な準備を経て、Llama3 シリーズ モデルがついに一般公開されたことを示しています。
Llama3.1405B は、1,280 億のパラメーターを備えた多言語ツール使用モデルです。 8K のコンテキスト長で事前トレーニングした後、モデルは 128K のコンテキスト長でさらにトレーニングされます。 Meta 氏によると、このモデルの複数のタスクにおけるパフォーマンスは、業界をリードする GPT-4 に匹敵します。
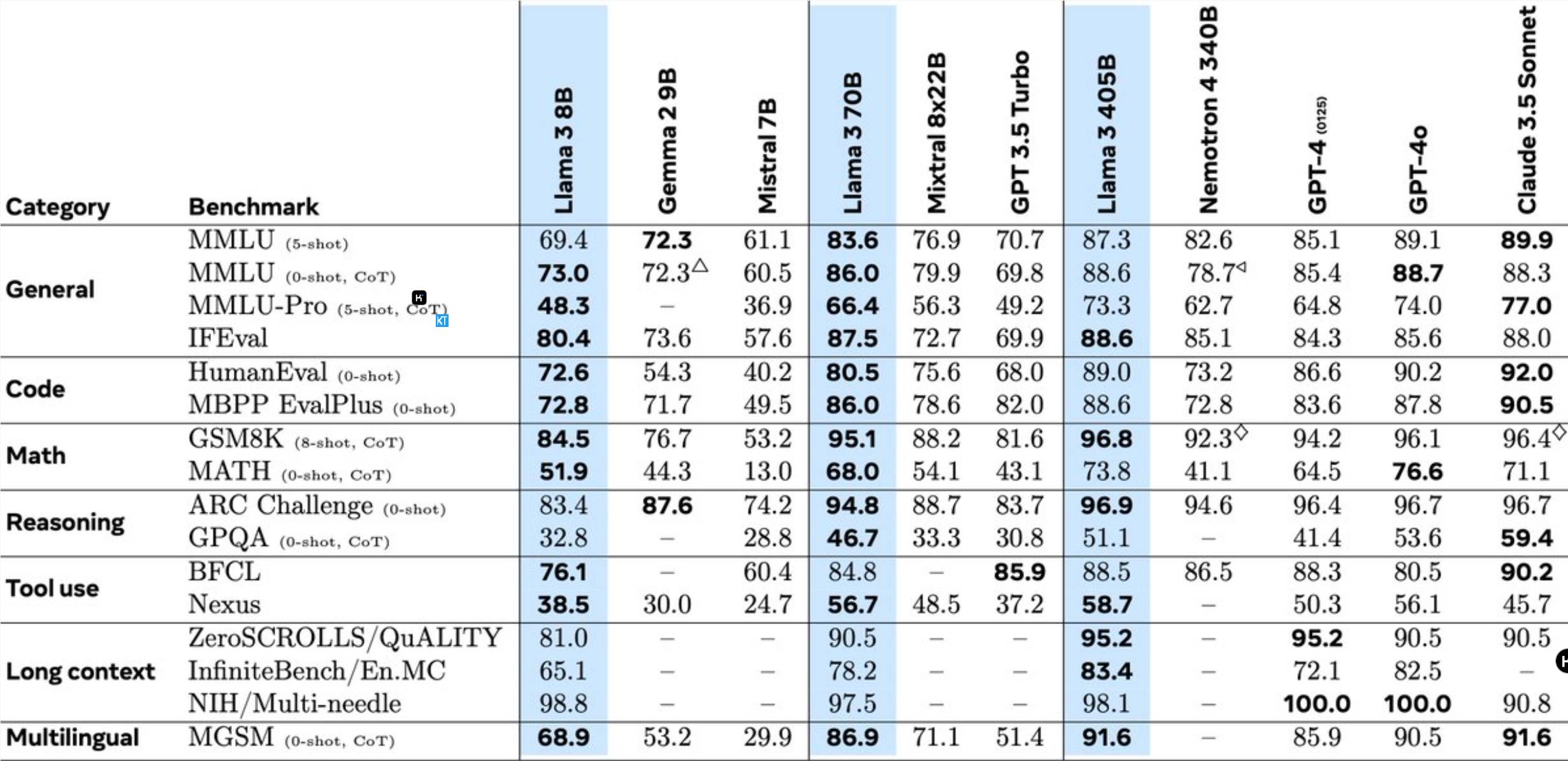
以前の Llama モデルと比較して、Meta は多くの点で最適化されています。
405B モデルの事前トレーニングは、15.6 兆個のトークンと 3.8x10^25 の浮動小数点演算を必要とする大きな課題です。この目的を達成するために、Meta はトレーニング アーキテクチャ全体を最適化し、16,000 個を超える H100 GPU を使用しました。
405B モデルの量産推論をサポートするために、Meta はモデルを 16 ビット (BF16) から 8 ビット (FP8) に量子化し、コンピューティング要件を大幅に削減し、単一のサーバー ノードでモデルを実行できるようにしました。
さらに、Meta は 405B モデルを使用して、70B および 8B モデルのトレーニング後の品質を向上させます。トレーニング後のフェーズでは、チームは教師あり微調整 (SFT)、拒否サンプリング、直接優先度の最適化など、複数回の調整プロセスを通じてチャット モデルを改良しました。ほとんどの SFT サンプルは合成データを使用して生成されることに注意してください。
Llama3 はまた、画像、ビデオ、および音声機能を統合し、組み合わせたアプローチを使用して、モデルが画像とビデオを認識し、音声対話をサポートできるようにします。ただし、これらの機能はまだ開発中であり、正式にはリリースされていません。
Meta はライセンス契約も更新し、開発者が Llama モデルの出力を使用して他のモデルを改良できるようにしました。
Meta の研究者らは次のように述べています。業界トップの人材とともに AI の最前線で働き、研究結果をオープンかつ透明に公開できることは非常にエキサイティングです。オープンソース モデルがもたらす革新と、将来の Llama シリーズ モデルの可能性を楽しみにしています。
このオープンソースの取り組みは間違いなく AI 分野に新たな機会と課題をもたらし、大規模言語モデル技術のさらなる開発を促進するでしょう。
Llama 3.1 405B のオープンソースは、大規模言語モデル技術の進歩を大きく促進し、AI 分野にさらなる可能性をもたらすでしょう。開発者がこのモデルに基づいてさらに素晴らしいアプリケーションを作成することを楽しみにしています。