大規模な言語モデルの効率の向上は、人工知能の分野で常に研究のホットスポットとなっています。最近、Aleph Alpha、ダルムシュタット工科大学、その他の機関の研究チームは、大規模な言語モデルの操作効率を大幅に向上させる、T-FREE と呼ばれる新しい手法を開発しました。この方法は、スパース アクティベーションに文字トリプルを使用することで埋め込み層パラメーターの数を減らし、単語間の形態学的類似性を効果的にモデル化し、モデルのパフォーマンスを確保しながらコンピューティング リソースの消費を大幅に削減します。この画期的なテクノロジーは、大規模な言語モデルのアプリケーションに新たな可能性をもたらします。
研究チームは最近、T-FREE と呼ばれるエキサイティングな新しい手法を導入しました。これにより、大規模な言語モデルの操作効率が飛躍的に向上します。 Aleph Alpha、ダルムシュタット工科大学、hessian.AI、およびドイツ人工知能研究センター (DFKI) の科学者が共同でこの素晴らしいテクノロジーを発表しました。正式名称は「タガーフリーのスパース表現、メモリ効率の高い埋め込みが可能」です。
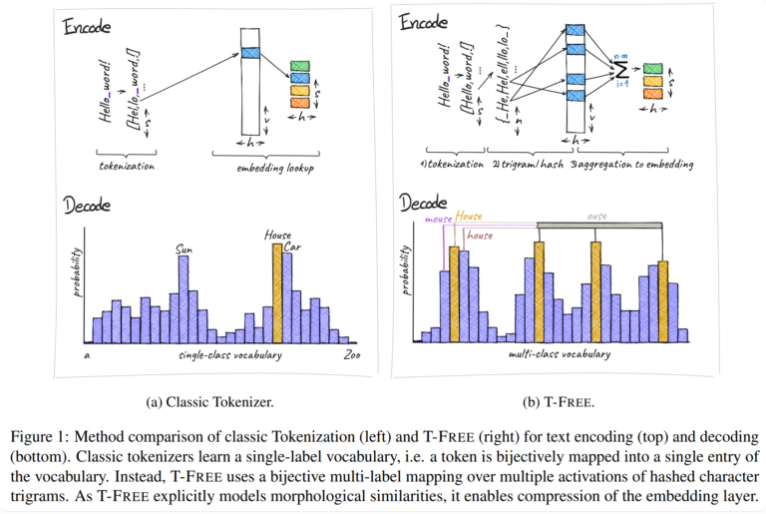
従来、トークナイザーを使用してテキストをコンピューターが理解できる数値形式に変換していましたが、T-FREE は別の道を選択しました。これは、文字トリプル (いわゆる「トリプル」) を使用して、スパース アクティベーションを通じて単語をモデルに直接埋め込みます。この革新的な動きの結果、埋め込み層のパラメーターの数は驚くべきことに 85% 以上削減されましたが、テキスト分類や質問応答などのタスクを処理する際、モデルのパフォーマンスはまったく影響を受けませんでした。
T-FREE のもう 1 つのハイライトは、単語間の形態学的類似性を非常に巧妙にモデル化していることです。私たちが日常生活で頻繁に目にする「家」、「家」、「家庭」という言葉と同じように、T-FREE はこれらの類似した言葉をモデル内でより効果的に表現できます。研究者らは、より高い圧縮率を達成するには、類似した単語を互いに近くに埋め込む必要があると考えています。したがって、T-FREE は埋め込み層のサイズを削減するだけでなく、テキストの平均エンコード長も 56% 削減します。
さらに注目すべき点は、T-FREE が異なる言語間の転移学習で特に優れたパフォーマンスを発揮することです。ある実験では、研究者らは 30 億のパラメータを持つモデルを使用し、最初に英語、次にドイツ語でトレーニングしたところ、T-FREE が従来のタガーベースの手法よりもはるかに適応性が高いことがわかりました。
しかし、研究者らは現在の結果については控えめなままだ。彼らは、これまでの実験は最大 30 億のパラメーターを持つモデルに限定されており、将来的にはより大きなモデルとより大きなデータセットでのさらなる評価が計画されていることを認めています。
T-FREE 法の出現は、大規模な言語モデルの効率を向上させるための新しいアイデアを提供し、計算コストの削減とモデルのパフォーマンスの向上における利点は注目に値します。今後の研究の方向性は、T-FREE の適用範囲をさらに拡大し、大規模言語モデル技術の継続的な開発を促進するために、大規模なモデルとデータセットの検証に焦点を当てていく予定です。近い将来、T-FREEはさらに多くの分野で重要な役割を果たすと考えられます。