人工知能の急速な発展に伴い、軽量かつ効率的なユーザー インターフェイス理解テクノロジーが AI アプリケーションの鍵となっています。最近発表された研究論文の中で、Apple は UI-JEPA と呼ばれる新しいアーキテクチャを導入しました。これは、軽量デバイスでの効率的な UI 理解の問題を解決することを目的としています。このテクノロジーは、高いパフォーマンスを維持するだけでなく、コンピューティング要件を大幅に軽減し、リソースに制約のあるデバイス上で AI アプリケーションを実行するための新たな可能性を提供します。 UI-JEPAの登場により、より便利でプライベートなAIアプリケーションの普及が進むことが期待されます。
人工知能テクノロジーが進歩し続けるにつれて、直感的で便利な AI アプリケーションを作成する上で、ユーザー インターフェイス (UI) の理解が重要な課題となっています。最近、Apple の研究者は、新しい論文で UI-JEPA を紹介しました。これは、高性能を維持するだけでなく、UI の計算要件を大幅に削減する軽量のデバイス側 UI 理解を実現するように設計されたアーキテクチャです。
UI を理解する際の課題は、画像や自然言語などのクロスモーダルな特徴を処理して、UI シーケンスの時間的関係をキャプチャする必要があることにあります。 Anthropic Claude3.5Sonnet や OpenAI GPT-4Turbo などのマルチモーダル大規模言語モデル (MLLM) は、パーソナライズされた計画において進歩を遂げていますが、これらのモデルは広範なコンピューティング リソースと巨大なモデル サイズを必要とし、高い遅延を引き起こすため、低遅延を必要とする軽量デバイス ソリューションには適していません。遅延とプライバシーの強化。
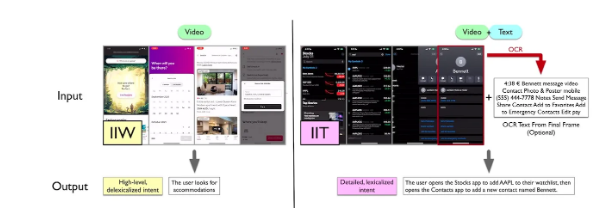
UI-JEPA の IIT および IIW データセットのサンプル画像ソース: arXiv
UI 理解に関する研究をさらに進めるために、研究者は 2 つの新しいマルチモーダル データセットとベンチマーク、「Intentions in the Wild」(IIW) と「Intentions in the Tame」(IIT) を導入しました。 IIW はユーザーの意図が曖昧な無制限の UI アクション シーケンスをキャプチャしますが、IIT はより明確な意図を持つ一般的なタスクに焦点を当てます。
新しいベンチマークで UI-JEPA のパフォーマンスを評価すると、数ショット設定で他のビデオ エンコーダー モデルを上回り、大規模なクローズド モデルと同等のパフォーマンスを達成していることがわかります。研究者らは、光学式文字認識 (OCR) を使用して UI から抽出したテキストを結合すると、UI-JEPA のパフォーマンスがさらに向上することを発見しました。
UI-JEPA モデルの潜在的な用途には、AI エージェント向けの自動フィードバック ループの作成、人間の介入なしでインタラクションから継続的に学習できるようにすること、政府機関のフレームワーク内のさまざまなアプリケーションやモードにわたってユーザーの意図を追跡するように設計されたアプリケーションに UI-JEPA を統合することが含まれます。 。
Apple の UI-JEPA モデルは、Apple デバイスをよりスマートかつ効率的にするために設計された軽量の生成 AI ツールのスイートである Apple Intelligence に適しているようです。 Apple がプライバシーを重視していることを考えると、UI-JEPA モデルの低コストと追加の効率により、同社の AI アシスタントはクラウド モデルに依存する他のアシスタントよりも優位性を得ることができる可能性があります。
UI-JEPA の出現は、軽量のデバイス側 AI アプリケーションに新たな可能性をもたらし、プライバシー保護と効率的なコンピューティングにおけるその利点により、将来の AI 開発における幅広い応用の可能性がもたらされ、継続的な注目に値します。