Jina AI は、HTML をクリーンな Markdown に変換するために特別に設計された軽量言語モデルである Reader-LM をリリースしました。広告やスクリプトなどの乱雑なコンテンツを Web ページから効率的に削除し、複雑な正規表現や手動操作を行わずに、明確に構造化された Markdown ファイルを生成できます。 Reader-LM には、Reader-LM-0.5B と Reader-LM-1.5B の 2 つのバージョンがあり、どちらもリソースに制約のある環境でも効率的に実行できるように最適化されており、最大 256K トークンのコンテキストをサポートします。
Jina AI は、元の HTML コンテンツをクリーンできちんとした Markdown 形式に変換するために特別に設計された 2 つの小さな言語モデルを発表しました。これにより、退屈な Web ページのデータ処理が不要になります。
Reader-LM と呼ばれるこのモデルの最大のハイライトは、Web コンテンツを迅速かつ効率的に Markdown ファイルに変換できることです。
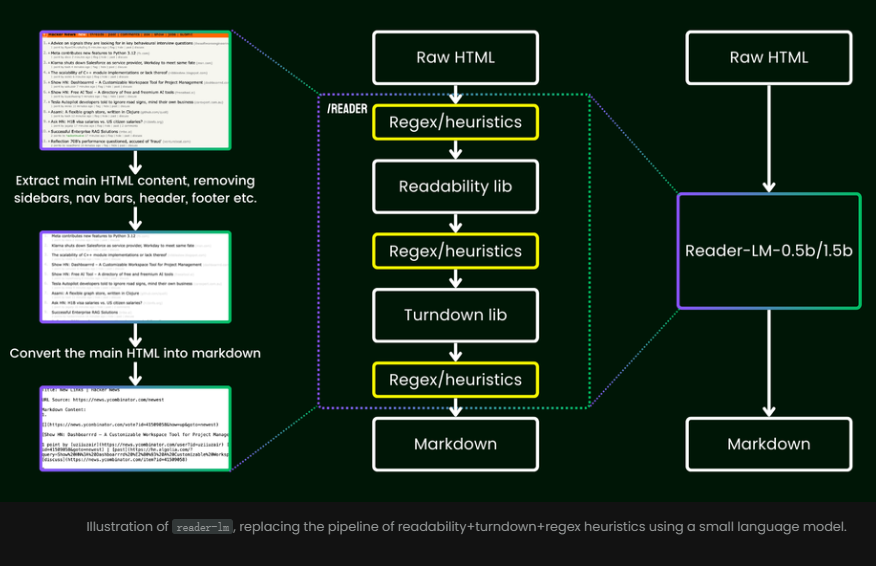
これを使用する利点は、複雑なルールや面倒な正規表現に依存する必要がなくなることです。これらのモデルは、広告、スクリプト、ナビゲーション バーなどの乱雑なコンテンツを Web ページからインテリジェントかつ自動的に削除し、最終的に明確で整理された Markdown 形式を提示します。
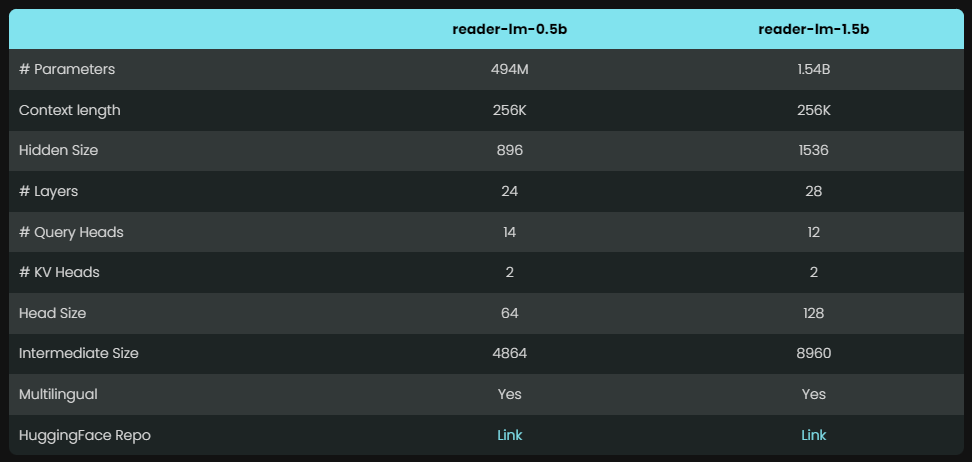
Reader-LM には、Reader-LM-0.5B と Reader-LM-1.5B という、パラメータの異なる 2 つのモデルが用意されています。これら 2 つのモデルのパラメーターの数はそれほど多くありませんが、HTML を Markdown に変換するタスク用に最適化されており、その結果は驚くべきものであり、そのパフォーマンスは多くの大規模な言語モデルを上回ります。
これらのモデルはコンパクトな設計により、リソースに制約のある環境でも効率的に動作できます。さらに優れているのは、Reader-LM が複数の言語をサポートしているだけでなく、最大 256,000 トークンのコンテキスト データを処理できるため、複雑な HTML ファイルでも簡単に処理できることです。
正規表現や手動設定に依存する従来の方法とは異なり、Reader-LM は、HTML データを自動的にクリーンアップして重要な情報を抽出するエンドツーエンドのソリューションを提供します。
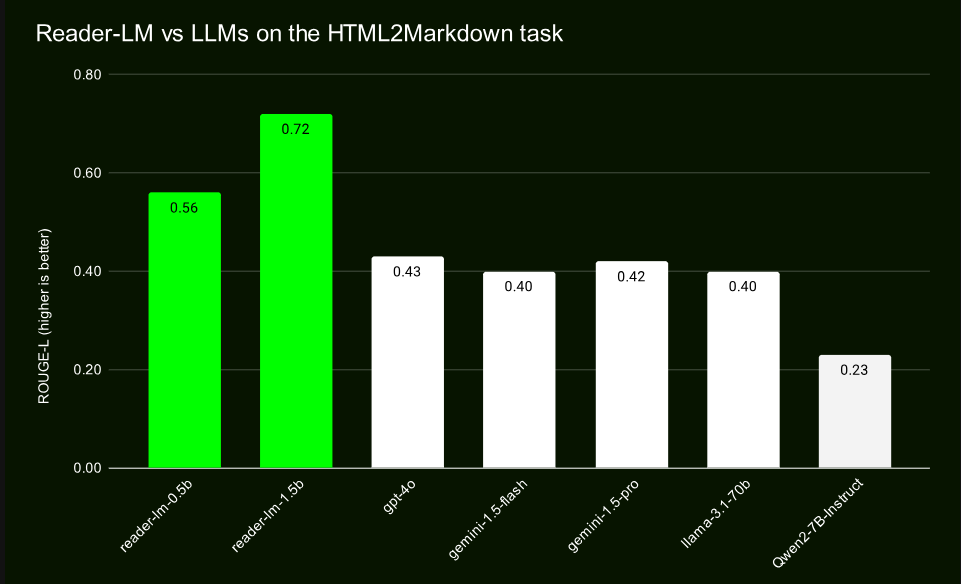
GPT-4 や Gemini などの大規模モデルとの比較テストを通じて、Reader-LM は、特に構造の保持と Markdown 構文の使用に関して優れたパフォーマンスを実証しました。 Reader-LM-1.5B は、ROUGE-L スコアが 0.72 と、さまざまな指標で特に優れたパフォーマンスを示し、コンテンツ生成の精度が高いことを示しており、エラー率も同様の製品に比べて大幅に低くなります。
Reader-LM はコンパクトな設計のため、ハードウェア リソースの使用量が軽く、特に 0.5B モデルは Google Colab のような低構成環境でもスムーズに動作します。 Reader-LM は、サイズが小さいにもかかわらず、強力な長いコンテキスト処理機能を備えており、パフォーマンスに影響を与えることなく、大規模で複雑な Web コンテンツを効率的に処理できます。
トレーニングに関して、Reader-LM は多段階プロセスを採用し、元のノイズの多い HTML から Markdown コンテンツを抽出することに重点を置いています。
トレーニング プロセスには、多数の実際の Web ページと合成データのペアリングが含まれており、モデルの効率と精度が保証されます。慎重に設計された 2 段階のトレーニングの後、Reader-LM は複雑な HTML ファイルを処理する能力を徐々に向上させ、繰り返し生成の問題を効果的に回避しました。
公式紹介: https://jina.ai/news/reader-lm-small- language-models-for-cleaning-and-converting-html-to-markdown/
全体として、Reader-LM は、HTML から Markdown への変換に効率的で便利かつ正確なソリューションを提供します。その軽量設計により、さまざまな環境で簡単に実行できるため、Web ページ データの処理に最適です。 詳しくは公式紹介リンクをご覧ください。