Kunlun Technology は最近、同社が開発した 2 つの報酬モデル、Skywork-Reward-Gemma-2-27B と Skywork-Reward-Llama-3.1-8B が RewardBench で優れた結果を達成し、27B モデルがリストのトップになったと発表しました。これは、Kunlun Wanwei が人工知能の分野、特に報酬モデルの研究開発において大きな進歩を遂げたことを示しており、大規模な言語モデルのトレーニングに新たな技術サポートを提供しています。報酬モデルは、モデル学習をガイドし、人間の好みにより沿ったコンテンツを生成できるため、強化学習において非常に重要です。 Kunlun Wanwei のモデルは、データ選択とモデル トレーニングにおいて独自の利点を備えており、対話やセキュリティなどの面で優れたパフォーマンスを発揮し、特に困難なサンプルを処理する場合に強力な機能を発揮します。
Kunlun Wanwei Technology Co., Ltd. は最近、同社が開発した 2 つの新しい報酬モデル、Skywork-Reward-Gemma-2-27B および Skywork-Reward-Llama-3.1-8B が、国際的に権威のある報酬モデルである RewardBench で良好なパフォーマンスを示したと発表しました。その中で、Skywork-Reward-Gemma-2-27B モデルがトップの座を獲得し、RewardBench 関係者から高く評価されました。
報酬モデルは強化学習の中核的な位置を占め、さまざまな状態でのエージェントのパフォーマンスを評価し、エージェントの学習プロセスをガイドする報酬信号を提供して、エージェントが特定の環境で最適な選択を行えるようにします。大規模な言語モデルのトレーニングでは、報酬モデルが特に重要な役割を果たし、モデルが人間の好みに合わせたコンテンツをより正確に理解して生成できるように支援します。
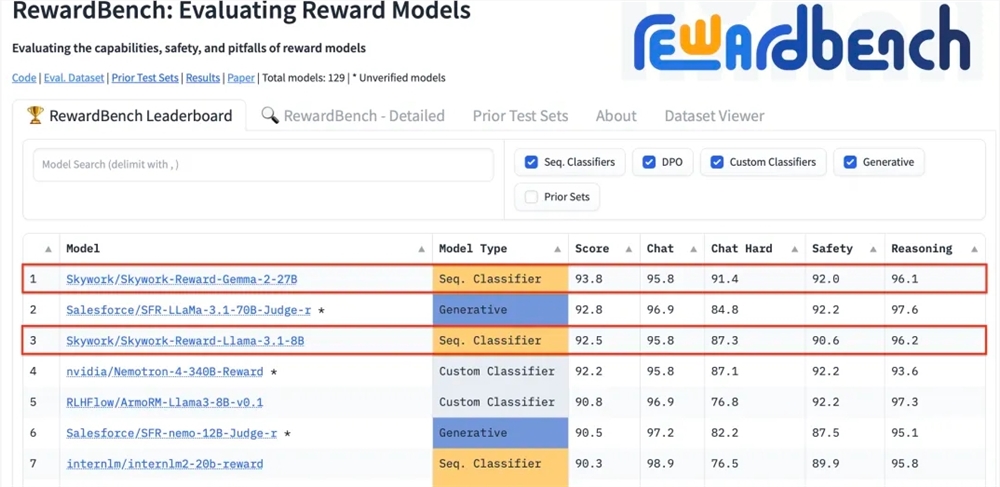
RewardBench は、大規模な言語モデルにおける報酬モデルの有効性を特に評価するベンチマーク リストで、対話、推論、セキュリティなどの複数のタスクを通じてモデルを包括的に評価します。このリストのテスト データ セットは、プロンプト ワード、選択された応答、および拒否された応答からなるトリプルで構成されており、応答を拒否する前に、報酬モデルが、拒否された応答の中で選択された応答を正しくランク付けできるかどうかをテストします。 。
Kunlun Wanwei の Skywork-Reward モデルは、慎重に選択された部分順序付けされたデータ セットと比較的小規模なベース モデルを通じて開発されており、既存の報酬モデルと比較すると、その部分順序付けされたデータはインターネット上の公開データのみから取得され、特定のフィルターを通じてフィルタリングされて高水準の報酬が得られます。 -品質の好みのデータセット。データはセキュリティ、数学、コードなどの幅広いトピックをカバーしており、データの客観性と報酬ギャップの重要性を確保するために手動で検証されます。
テスト後、Kunlun Wanwei の報酬モデルは対話やセキュリティなどの分野で優れたパフォーマンスを示し、特に困難なサンプルに直面した場合、正しい予測を示したのは Skywork-Reward-Gemma-2-27B モデルだけでした。この成果は、世界的な AI 分野における Kunlun Wanwei の技術力とイノベーション能力を示すものであり、AI テクノロジーの開発と応用に新たな可能性をもたらすものでもあります。
27Bモデルアドレス:
https://huggingface.co/Skywork/Skywork-Reward-Gemma-2-27B
8Bモデルアドレス:
https://huggingface.co/Skywork/Skywork-Reward-Llama-3.1-8B
RewardBench における Kunlun Wanwei の優れたパフォーマンスは、人工知能の分野における最先端のテクノロジーと革新的な能力を示しており、今後の大規模な言語モデルの開発に新たな方向性と可能性をもたらすことを期待しています。