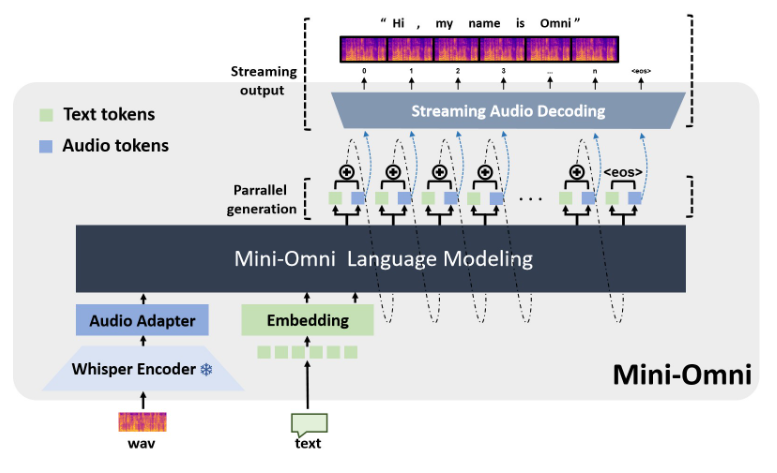
オープンソースのマルチモーダル大規模言語モデルである Mini-Omni は、音声対話テクノロジーに革命をもたらしています。高度なテクノロジーを統合してリアルタイムの音声入出力を実現し、思考と発話を同時に行う機能を備えており、より自然でスムーズな人間とコンピューターの対話体験をもたらします。 Mini-Omni の主な利点は、エンドツーエンドのリアルタイム音声処理機能にあり、スムーズな会話を楽しむために ASR モデルや TTS モデルを追加構成する必要はありません。複数のモーダル入力をサポートし、それらを柔軟に変換してさまざまな複雑なシナリオに適応し、多様なニーズに対応します。
現在、人工知能の急速な発展に伴い、Mini-Omni と呼ばれるオープンソースのマルチモーダル大規模言語モデルが音声インタラクション技術の革新をリードしています。複数の先進技術を統合したこの AI システムは、リアルタイムの音声入出力を可能にするだけでなく、思考と発話を同時に行うユニークな能力を備えており、ユーザーにこれまでにない自然なインタラクション体験をもたらします。
Mini-Omni の主な利点は、エンドツーエンドのリアルタイム音声処理機能にあります。ユーザーは、自動音声認識 (ASR) またはテキスト読み上げ (TTS) モデルを追加構成することなく、スムーズな音声会話を楽しむことができます。このシームレスなデザインにより、ユーザー エクスペリエンスが大幅に向上し、人間とコンピューターの対話がより自然かつ直観的になります。
Mini-Omni は音声機能に加えて、テキストなど複数のモードでの入力にも対応しており、異なるモードを柔軟に切り替えることができます。このマルチモーダル処理機能により、モデルはさまざまな複雑な対話シナリオに適応し、ユーザーの多様なニーズを満たすことができます。
特に注目すべきは、Mini-Omni の Any Model Can Talk 機能です。このイノベーションにより、他の AI モデルが Mini-Omni のリアルタイム音声機能を簡単に統合できるようになり、AI アプリケーションの可能性が大幅に広がります。これにより、開発者により多くの選択肢が提供されるだけでなく、AI テクノロジーの分野を超えた応用への道も開かれます。
性能面でもミニオムニは総合力を発揮します。音声認識 (ASR) や音声生成 (TTS) などの従来の音声タスクで優れたパフォーマンスを発揮するだけでなく、TextQA や SpeechQA などの複雑な推論機能を必要とするマルチモーダル タスクでも強力な可能性を示します。この包括的な機能により、Mini-Omni は、単純な音声コマンドから、深い思考を必要とする質問と回答のタスクに至るまで、さまざまな複雑な対話シナリオを処理できるようになります。
Mini-Omni の技術実装には、複数の高度な AI モデルとテクノロジーが組み込まれています。大規模な言語モデルの基礎として Qwen2 を使用し、トレーニングと推論に litGPT を使用し、オーディオ エンコードに Whisper を使用し、オーディオ デコードは snac が担当します。このマルチテクノロジー融合手法により、モデルの全体的なパフォーマンスが向上するだけでなく、さまざまなシナリオでの適応性も向上します。
開発者や研究者にとって、Mini-Omni は便利な使い方を提供します。簡単なインストール手順で、ユーザーはローカル環境で Mini-Omni を起動し、Streamlit や Gradio などのツールを使用してインタラクティブなデモンストレーションを実行できます。このオープンで使いやすい機能は、AI テクノロジーの普及と革新的なアプリケーションを強力にサポートします。
プロジェクトアドレス: https://github.com/gpt-omni/mini-omni
Mini-Omni は、強力な機能、便利な使用法、オープンソース機能を備え、AI 音声インタラクションの分野に新たな可能性をもたらし、開発者や研究者の注目と探求に値します。今後の展開にも注目だ。