Mamba チームの研究は、大きな Transformer モデル Llama をより効率的な Mamba モデルに「蒸留」することに成功しました。この研究では、漸進蒸留、教師あり微調整、方向優先最適化などのテクノロジーを巧みに組み合わせ、Mamba モデルの独自の構造に基づいた新しい推論デコード アルゴリズムを設計し、パフォーマンスを確保することなくモデルの推論速度を大幅に向上させました。ロスなく効率を実現しました。この研究は、大規模なモデルのトレーニングのコストを削減するだけでなく、重要な学術的意義と応用価値を持つ将来のモデル最適化のための新しいアイデアを提供します。
最近、Mamba チームの研究は注目を集めています。コーネル大学やプリンストン大学などの大学の研究者は、大規模な Transformer モデルである Llama を Mamba に「蒸留」することに成功し、モデルの推論速度を大幅に向上させる新しい推論デコード アルゴリズムを設計しました。
研究者の目標は、ラマをマンバに変えることです。なぜこれを行うのでしょうか?大規模なモデルを最初からトレーニングするのは費用がかかり、Mamba はその誕生以来広く注目を集めていますが、大規模な Mamba モデルを実際にトレーニングするチームはほとんどないからです。市場には AI21 の Jamba や NVIDIA の Hybrid Mamba2 など、評判の高い亜種がいくつかありますが、多くの成功した Transformer モデルには豊富な知識が組み込まれています。この知識を固定して、Transformer を Mamba に合わせて微調整できれば、問題は解決されるでしょう。
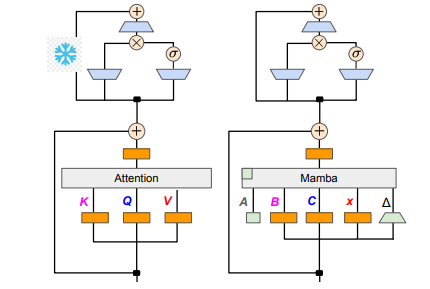
研究チームは、漸進的蒸留、教師付き微調整、方向性優先最適化などのさまざまな方法を組み合わせることにより、この目標を達成することに成功しました。パフォーマンスを損なうことなく、速度も重要であることは注目に値します。 Mamba には長いシーケンス推論において明らかな利点があり、Transformer には投機的デコードなどの推論高速化ソリューションもあります。 Mamba の独自の構造はこれらのソリューションを直接適用できないため、研究者らは特別に新しいアルゴリズムを設計し、それをハードウェア機能と組み合わせて Mamba ベースの投機的デコーディングを実装しました。
最後に、研究者らは Zephyr-7B と Llama-38B を線形 RNN モデルに変換することに成功し、その性能は蒸留前の標準モデルと同等でした。トレーニング プロセス全体で使用されるのは 200 億トークンのみで、結果は 1.2T トークンを使用して最初からトレーニングされた Mamba7B モデルや 3.5T トークンでトレーニングされた NVIDIA Hybrid Mamba2 モデルに匹敵します。
技術的な詳細に関しては、線形 RNN と線形アテンションは関連しているため、研究者はアテンション メカニズムで射影行列を直接再利用し、パラメーターの初期化を通じてモデルの構築を完了できます。さらに、研究チームは、Transformer の MLP 層のパラメータを凍結し、アテンション ヘッドを線形 RNN 層 (つまり Mamba) に徐々に置き換え、ヘッド間で共有されるキーと値のグループ クエリ アテンションを処理しました。
蒸留プロセス中に、注目層を徐々に置き換える戦略が採用されます。教師あり微調整には 2 つの主な方法が含まれます。1 つは単語レベルの KL 発散に基づくもので、もう 1 つはシーケンス レベルの知識の蒸留です。ユーザー設定の調整フェーズでは、チームは Direct Preference Optimization (DPO) メソッドを使用して、コンテンツ生成時に教師モデルの出力と比較することで、モデルがユーザーの期待をより適切に満たせることを確認しました。
次に、研究者らは、Transformer の投機的デコーディングを Mamba モデルに適用し始めました。投機的デコードは、小規模なモデルを使用して複数の出力を生成し、その後、大規模なモデルを使用してこれらの出力を検証することとして単純に理解できます。小さなモデルは高速に実行され、複数の出力ベクトルを迅速に生成できますが、大きなモデルはこれらの出力の精度を評価する役割を担うため、全体的な推論速度が向上します。
このプロセスを実装するために、研究者らは、小規模モデルを使用して毎回 K 個のドラフト出力を生成し、その後、大規模モデルが検証を通じて最終出力と中間状態のキャッシュを返す一連のアルゴリズムを設計しました。この方法は GPU 上で良好な結果をもたらし、Mamba2.8B は 1.5 倍の推論加速を達成し、受け入れ率は 60% に達しました。アーキテクチャの異なるGPUによって効果は異なりますが、研究チームはカーネルの統合や実装方法の調整によってさらに最適化を進め、最終的に理想的な高速化効果を実現しました。
実験段階では、研究者らは Zephyr-7B と Llama-3Instruct8B を使用して 3 段階の蒸留トレーニングを実施し、最終的には 8 枚のカード 80G A100 で実行するのにわずか 3 ~ 4 日しかかかりず、研究結果を再現することに成功しました。この研究は、Mamba と Llama 間の変換を示すだけでなく、将来のモデルの推論速度とパフォーマンスを向上させるための新しいアイデアも提供します。
論文アドレス: https://arxiv.org/pdf/2408.15237
この研究は、大規模言語モデルの効率を向上させるための貴重な経験と技術的ソリューションを提供し、その結果はより多くの分野に適用され、人工知能技術のさらなる発展を促進することが期待されます。論文アドレスの提供により、読者は研究内容をより深く理解することができます。