学術界では、虚偽論文の蔓延が深刻な問題となっており、科学研究の進歩や知識の普及に重大な支障をきたしている。この課題に対処するために、ニューヨーク州ビンガムトン大学の研究者アーメド・アブディン・ハメード氏は、xFakeSci と呼ばれる機械学習アルゴリズムを開発しました。これは、偽の学術論文を効果的に特定し、学術的完全性を維持するための新しい技術的手段を提供します。この記事では、xFakeSci アルゴリズムの原理、応用、将来の開発の方向性を深く探求し、学術不正と戦う上でのその大きな可能性を示します。
今日の情報爆発の時代、特に科学研究の分野では、偽論文の出現を防ぐのは困難です。
最近、ニューヨーク州ビンガムトン大学の研究者アーメド・アブディーン・ハメド氏は、偽造学術論文を最大 94% の精度で識別できる xFakeSci と呼ばれる機械学習アルゴリズムを開発しました。
ハミード氏は、自身の主な研究方向は生物医学情報学であり、感染症流行中は偽の科学研究論文が後を絶たないと述べた。
彼と彼のチームは大量の実験を行い、アルツハイマー病、がん、うつ病という 3 つの人気のある医療トピックに関する 50 の偽記事を作成し、同じトピックに関する本物の記事との比較分析を実施しました。このようにして、彼は違いやパターンを発見したいと考えています。
研究の過程で、ハメード氏は国立衛生研究所の PubMed データベースを使用して関連文献を抽出し、同じキーワードを使用して ChatGPT に論文の生成をリクエストしました。彼の直観は、偽の論文と本物の論文の間には何らかのパターンがあるに違いないと言いました。
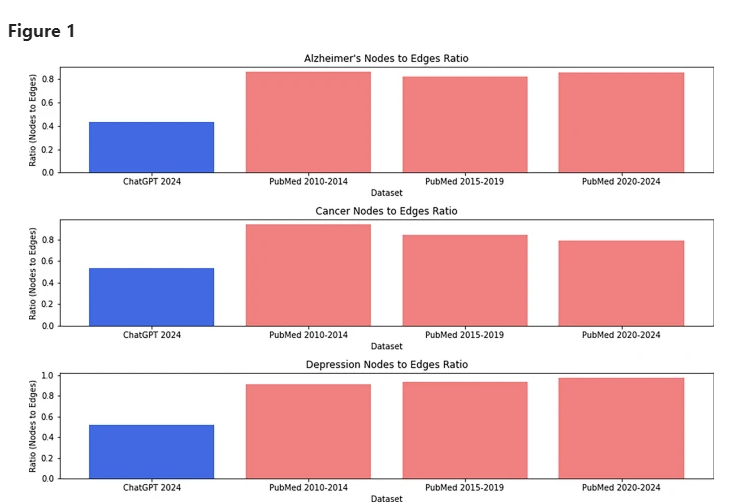
さまざまなデータセット ChatGPT および科学論文のノード対エッジの比率。
徹底的な分析の結果、xFakeSci アルゴリズムは主に 2 つの主要な機能に焦点を当てています。1 つは、「気候変動」や「臨床試験」などの記事内のバイグラム、もう 1 つは、これらのバイグラムと他の単語や単語との関連です。概念。
彼は、偽の論文に出現するダブルワードの組み合わせの数が、偽の論文の他の内容と密接に関連しているにもかかわらず、本物の論文に出現するダブルワードの組み合わせの数よりも大幅に少ないことを発見しました。
同氏は、AIが生成した論文は多くの場合、読者を説得するようにデザインされているのに対し、人間の研究者の目標は実験結果と方法を真実に報告することであると指摘した。
ハメド氏は将来的に、xFakeSciアルゴリズムを工学、科学、人文科学などのより多くの分野に拡張し、偽論文の特徴が一貫しているかどうかを検証する予定だ。同氏は、AI技術の継続的な進歩により、真偽の論文を識別することは今後もさらに困難になるだろうと強調した。したがって、包括的なソリューションを設計することが特に重要です。
現在のアルゴリズムは偽造論文の 94% を検出できますが、それでも 6% の偽造論文がネットをすり抜ける可能性があります。同氏は、重要な進歩は見られたものの、認識率を向上させ、国民の意識を高めるにはまだ継続的な努力が必要であると謙虚に語った。
論文入口: https://www.nature.com/articles/s41598-024-66784-6
ハイライト:
** 新しいツール xFakeSci は、偽の科学研究論文を最大 94% の精度で特定し、科学研究を保護します。 **
? ** 研究者たちは大量の偽の論文を作成し、それらを本物の論文と比較したところ、両者の間には書き方に大きな違いがあることがわかりました。 **
** 将来的には、AI 生成論文のますます複雑化する課題に対応するために、アルゴリズムの適用範囲が拡大される予定です。 **
xFakeSci アルゴリズムの出現は、学術不正と闘うための強力な武器を提供しますが、依然として継続的に改良を続ける必要があります。 テクノロジーの進歩と学術の完全性の維持には、より健全な学術エコシステムを構築するための共同の取り組みが必要です。