Google DeepMind は、多くの大学と協力して、生成報酬モデル (GenRM) と呼ばれる新しい手法を開発しました。これは、推論タスクにおける生成 AI の精度と信頼性が不十分であるという問題を解決することを目的としています。既存の生成AIモデルは自然言語処理などの分野で広く使われていますが、特に極めて高い精度が要求される分野では誤った情報を自信をもって出力してしまうことが多く、適用範囲が限られています。 GenRM のイノベーションは、検証プロセスを次の単語予測タスクとして再定義し、大規模言語モデル (LLM) のテキスト生成機能を検証プロセスに統合し、連鎖推論をサポートすることで、より包括的かつ体系的な検証を実現することです。
最近、Google DeepMind の研究チームは多くの大学と協力して、推論タスクにおける生成 AI の精度と信頼性を向上させることを目的とした生成報酬モデル (GenRM) と呼ばれる新しい手法を提案しました。
生成 AI は、主に、一連の単語の次の単語を予測することで、一貫したテキストを生成するなど、多くの分野で広く使用されています。ただし、これらのモデルは自信を持って誤った情報を出力することがあります。これは、特に教育、金融、医療などの精度が重要な分野では大きな問題です。
現在、研究者たちは、生成 AI モデルが出力精度において直面する問題に対して、さまざまな解決策を試みています。このうち、判別報酬モデル (RM) は、スコアに基づいて潜在的な回答が正しいかどうかを判断するために使用されますが、この方法では大規模言語モデル (LLM) の生成機能を十分に活用できません。もう 1 つの一般的に使用される方法は、「裁判官としての LLM」ですが、この方法は、複雑な推論タスクを解決する場合、プロの検証者ほど効果的ではないことがよくあります。
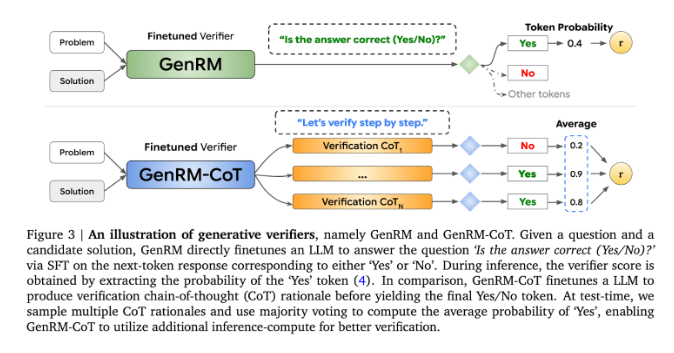
GenRM の革新性は、検証プロセスを次の単語予測タスクとして再定義することです。これは、従来の差別的報酬モデルとは異なり、GenRM は LLM のテキスト生成機能を検証プロセスに組み込み、モデルが潜在的なソリューションの生成と評価を同時に行うことを可能にすることを意味します。さらに、GenRM は連鎖推論 (CoT) もサポートしています。つまり、モデルは最終結論に達する前に中間推論ステップを生成できるため、検証プロセスがより包括的かつ体系的になります。
GenRM アプローチでは、生成と検証を組み合わせることで、トレーニング中にモデルの生成と検証の機能を同時に向上できる統合トレーニング戦略が採用されています。実際のアプリケーションでは、モデルは最終的な答えを検証するために使用される中間推論ステップを生成します。
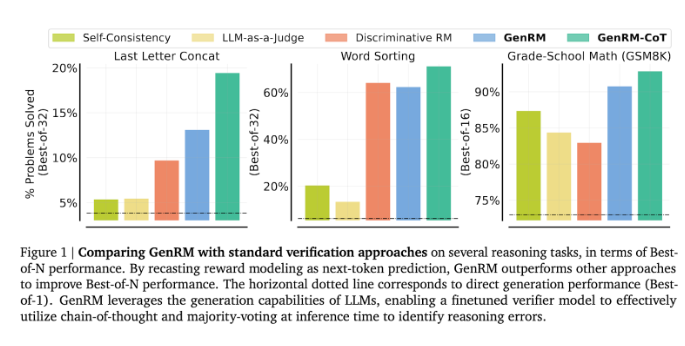
研究者らは、GenRM モデルが就学前の算数やアルゴリズムの問題解決タスクの精度が大幅に向上するなど、いくつかの厳密なテストで良好なパフォーマンスを示したことを発見しました。差別的報酬モデルと判定方法としての LLM と比較して、GenRM の問題解決成功率は 16% から 64% 増加しました。
たとえば、Gemini1.0Pro モデルの出力を検証した場合、GenRM は問題解決の成功率を 73% から 92.8% に向上させました。
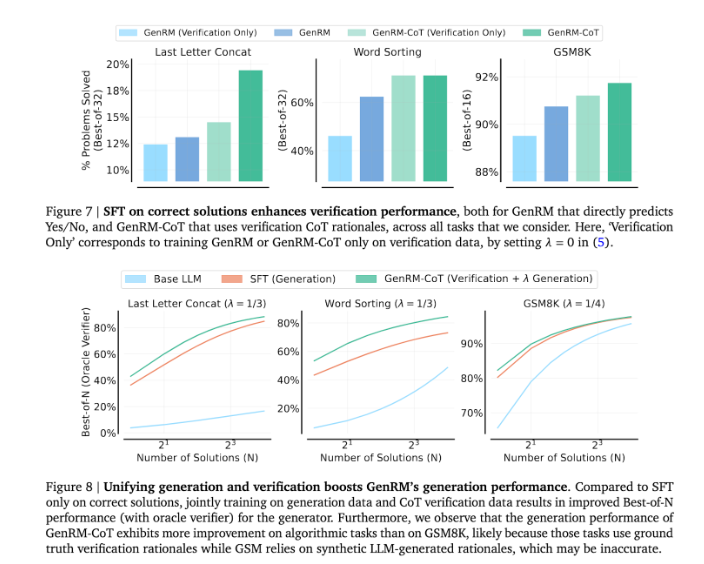
GenRM 手法の導入は、生成 AI 分野における大きな進歩を示し、ソリューションの生成と検証を 1 つのプロセスに統合することで、AI によって生成されたソリューションの精度と信頼性が大幅に向上します。
全体として、GenRM の出現は、生成 AI の信頼性を向上させるための新しいアイデアを提供します。複雑な推論問題の解決における大幅な改善は、生成 AI がより多くの分野に適用される可能性を示しており、さらなる研究と探索に値します。