データベース クエリ オプティマイザーは、カーディナリティ推定 (CE) に大きく依存してクエリ結果のサイズを予測し、最適な実行プランを選択します。カーディナリティの推定が不正確であると、クエリのパフォーマンスが低下する可能性があります。既存の CE メソッドには、特に複雑なクエリを処理する場合に制限があります。学習 CE モデルはより正確ですが、トレーニング コストが高く、体系的なベンチマーク評価が不足しています。
最新のリレーショナル データベースでは、カーディナリティ推定 (CE) が重要な役割を果たします。簡単に言えば、カーディナリティの推定は、データベース クエリが返す中間結果の数を予測することです。この予測は、結合順序の決定、インデックスを使用するかどうか、最適な結合方法の選択など、クエリ オプティマイザーの実行計画の選択に大きな影響を与えます。カーディナリティの推定が不正確な場合、実行計画が大きく損なわれる可能性があり、その結果、クエリ速度が極端に遅くなり、データベース全体のパフォーマンスに重大な影響を与える可能性があります。
ただし、既存のカーディナリティ推定方法には多くの制限があります。従来の CE テクノロジーは、いくつかの単純化された仮定に依存しており、多くの場合、特に複数のテーブルや条件が関係する場合に、複雑なクエリのカーディナリティを正確に予測します。 CE モデルを学習すると精度が向上しますが、トレーニング時間が長いこと、大規模なデータセットが必要であること、体系的なベンチマーク評価が欠如していることにより、その応用は制限されています。
このギャップを埋めるために、Google の研究チームは新しいベンチマーク フレームワークである CardBench を立ち上げました。 CardBench には、以前のベンチマークをはるかに上回る 20 を超える現実世界のデータベースと数千のクエリが含まれています。これにより、研究者は、さまざまな条件下でさまざまな学習 CE モデルを体系的に評価および比較することができます。このベンチマークは、さまざまなトレーニング ニーズに適した、インスタンス ベースのモデル、ゼロショット モデル、および微調整されたモデルの 3 つの主要な設定をサポートしています。
CardBench は、必要な統計を計算し、実際の SQL クエリを生成し、CE モデルをトレーニングするための注釈付きクエリ グラフを作成できる一連のツールを含むように設計されています。
このベンチマークは 2 つのトレーニング データ セットを提供します。1 つは複数のフィルター述部を含む単一のテーブル クエリ用で、もう 1 つは 2 つのテーブルを含むバイナリ結合クエリ用です。このベンチマークには、小規模なデータセットの 1 つに対する 9125 の単一テーブル クエリと 8454 のバイナリ結合クエリが含まれており、モデル評価のための堅牢かつ困難な環境が保証されています。 Google BigQuery からのトレーニング データ ラベルには 7 CPU 年のクエリ実行時間が必要であり、このベンチマークの作成に多大な計算投資が費やされていることがわかります。これらのデータセットとツールを提供することで、CardBench は研究者が新しい CE モデルを開発およびテストする障壁を下げます。
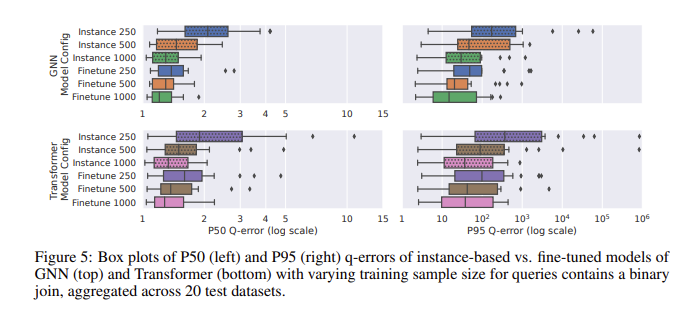
CardBench を使用したパフォーマンス評価では、ファインチューニングされたモデルが特に優れたパフォーマンスを示しました。ゼロショット モデルは、特に結合を含む複雑なクエリで、目に見えないデータセットに適用すると精度を向上させるのに苦労しますが、微調整されたモデルは、はるかに少ないトレーニング データでインスタンス ベースの手法と同等の精度を達成できます。たとえば、微調整されたグラフ ニューラル ネットワーク (GNN) モデルは、バイナリ結合クエリで q エラー中央値 1.32、95 パーセンタイル q エラー 120 を達成し、ゼロショット モデルよりも大幅に優れています。結果は、500 クエリを使用した場合でも、事前トレーニングされたモデルを微調整することでパフォーマンスを大幅に向上できることを示しています。これにより、トレーニング データが制限される可能性がある実際のアプリケーションに適しています。
CardBench の導入により、学習カーディナリティ推定の分野に新たな希望がもたらされ、研究者がモデルをより効果的に評価および改善できるようになり、この重要な分野のさらなる発展が促進されます。
論文の入り口: https://arxiv.org/abs/2408.16170
つまり、CardBench は包括的で強力なベンチマーク フレームワークを提供し、学習カーディナリティ推定モデルの研究開発に重要なツールとリソースを提供し、データベース クエリ最適化テクノロジの進歩を促進します。 微調整されたモデルの優れたパフォーマンスは特に注目に値し、実用的なアプリケーションシナリオに新たな可能性をもたらします。