アリババは、第2世代のビジュアル言語モデルQwen2-VLをオープンソース化し、開発者が利用しやすいようにAPIインターフェースとオープンソースコードを提供すると発表した。このモデルは画像とビデオの理解において大幅な進歩を遂げ、複数の言語をサポートし、携帯電話やロボットを自律的に操作できる強力なビジュアルエージェント機能を備えています。 Qwen2-VL は、さまざまなアプリケーション シナリオのニーズを満たすために 2B、7B、72B の 3 つのサイズのモデルを提供しており、72B モデルはほとんどのインジケーターで最高のパフォーマンスを発揮し、2B モデルはモバイル アプリケーションに適しています。
9 月 2 日、Tongyi Qianwen は第 2 世代ビジュアル言語モデル Qwen2-VL のオープンソースを発表し、ユーザーが直接呼び出せる 2B および 7B サイズとその定量化バージョン モデルの API を Alibaba Cloud Bailian プラットフォーム上で公開しました。
Qwen2-VL モデルは、さまざまな側面で総合的なパフォーマンスの向上を実現します。さまざまな解像度やアスペクト比の画像を理解でき、DocVQA、RealWorldQA、MTVQAなどのベンチマークテストで世界トップクラスのパフォーマンスを達成しています。さらに、このモデルは 20 分を超える長いビデオも理解でき、ビデオベースの Q&A、対話、およびコンテンツ作成アプリケーションをサポートします。 Qwen2-VL は強力なビジュアル インテリジェンス機能も備えており、携帯電話やロボットを自律的に操作して複雑な推論や意思決定を実行できます。
このモデルは、中国語、英語、ほとんどのヨーロッパ言語、日本語、韓国語、アラビア語、ベトナム語などを含む、画像やビデオ内の多言語テキストを理解できます。 Tongyi Qianwen チームは、総合的な大学の質問、数学的能力、文書、表、多言語テキストと画像の理解、一般的な場面の質疑応答、ビデオの理解、エージェントの能力を含む 6 つの側面からモデルの機能を評価しました。
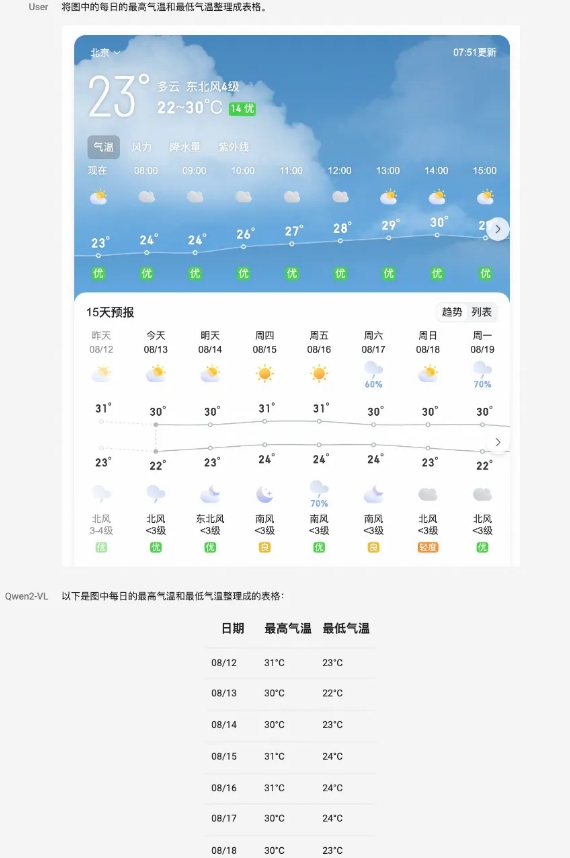
Qwen2-VL-72B はフラッグシップ モデルとして、ほとんどのインジケーターで最適なレベルに達しています。 Qwen2-VL-7B は、経済的なパラメータ スケールにより競争力の高いパフォーマンスを実現します。一方、Qwen2-VL-2B は豊富なモバイル アプリケーションをサポートし、完全な画像およびビデオの多言語理解機能を備えています。
モデル アーキテクチャに関しては、Qwen2-VL は ViT に Qwen2 を加えたシリーズ構成を継承しており、3 つのサイズのモデルすべてに 600M ViT が使用され、画像とビデオの統合入力をサポートします。モデルの視覚情報の認識とビデオ理解機能を向上させるために、チームはネイティブ動的解像度の完全サポートの実装やマルチモーダル回転位置埋め込み (M-ROPE) メソッドの使用など、アーキテクチャをアップグレードしました。
Alibaba Cloud Bailian プラットフォームは、ユーザーが直接呼び出すことができる Qwen2-VL-72B API を提供します。同時に、Qwen2-VL-2B および Qwen2-VL-7B のオープンソース コードは、Hugging Face Transformers、vLLM、およびその他のサードパーティ フレームワークに統合されており、開発者はこれらのプラットフォームを通じてモデルをダウンロードして使用できます。
Alibaba Cloud Bailian プラットフォーム:
https://help.aliyun.com/zh/model-studio/developer-reference/qwen-vl-api
GitHub:
https://github.com/QwenLM/Qwen2-VL
ハグフェイス:
https://huggingface.co/collections/Qwen/qwen2-vl-66cee7455501d7126940800d
マジックモデルスコープ:
https://modelscope.cn/organization/qwen?tab=model
モデル経験:
https://huggingface.co/spaces/Qwen/Qwen2-VL
つまり、Qwen2-VL モデルのオープン ソースは、開発者に強力なツールを提供し、ビジュアル言語モデル テクノロジの開発を促進し、さまざまなアプリケーション シナリオにさらなる可能性をもたらします。 開発者は、提供されたリンクからモデルとコードを入手して、独自のアプリケーションの構築を開始できます。