最近、Cureus 誌に掲載された研究では、OpenAI の GPT-4 モデルが追加のトレーニングなしで日本の理学療法士国家試験に合格したことが示されました。研究者らは、記憶、理解、応用、分析、評価を含む 1,000 の質問を使用して GPT-4 をテストし、その結果、正解率が 73.4% で、5 つのテスト パートすべてに合格したことがわかりました。この研究は、医療用途における GPT-4 の可能性について懸念を生じさせると同時に、実際的な問題や画像表を含む問題など、特定の種類の問題を扱う際の GPT-4 の限界も明らかにしています。
Cureus 誌に掲載された最近の査読済み研究では、OpenAI の GPT-4 言語モデルが追加のトレーニングなしで日本の理学療法士国家試験に合格したことが示されています。
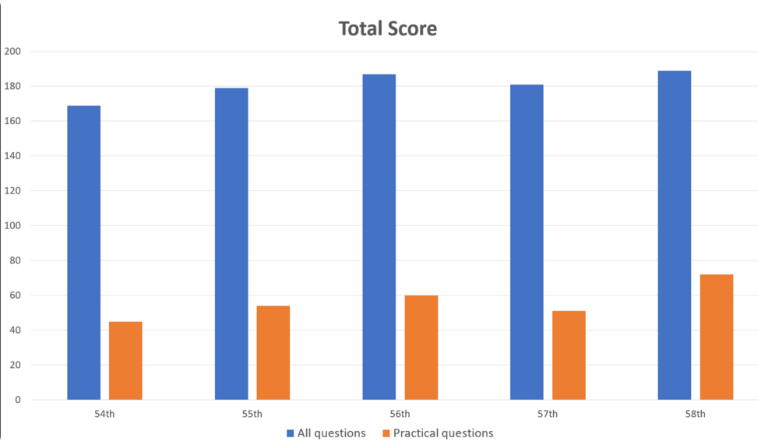
研究者らは、記憶、理解、応用、分析、評価などの分野をカバーする 1,000 の質問を GPT-4 に入力しました。その結果、GPT-4 は全体で質問の 73.4% に正解し、5 つのテスト パートすべてに合格したことがわかりました。ただし、研究により、一部の分野では AI の限界も明らかになりました。

GPT-4 は、一般的な問題では 80.1% の精度で良好なパフォーマンスを示しましたが、実際の問題ではわずか 46.6% でした。同様に、画像や表を含む質問 (正解率 35.4%) よりも、テキストのみの質問 (正解率 80.5%) の方がはるかに優れています。この発見は、GPT-4 の視覚的理解の限界に関する以前の研究と一致しています。
質問の難易度やテキストの長さは GPT-4 のパフォーマンスにほとんど影響を与えないことに注意してください。モデルは主に英語データを使用してトレーニングされましたが、日本語入力を処理する場合にも良好なパフォーマンスを発揮しました。
研究者らは、この研究は臨床リハビリテーションと医学教育におけるGPT-4の可能性を実証しているものの、慎重に検討する必要があると指摘した。彼らは、GPT-4 がすべての質問に正しく答えるわけではなく、新しいバージョンと筆記テストおよび推論テストにおけるモデルの機能の将来の評価が必要であることを強調しました。
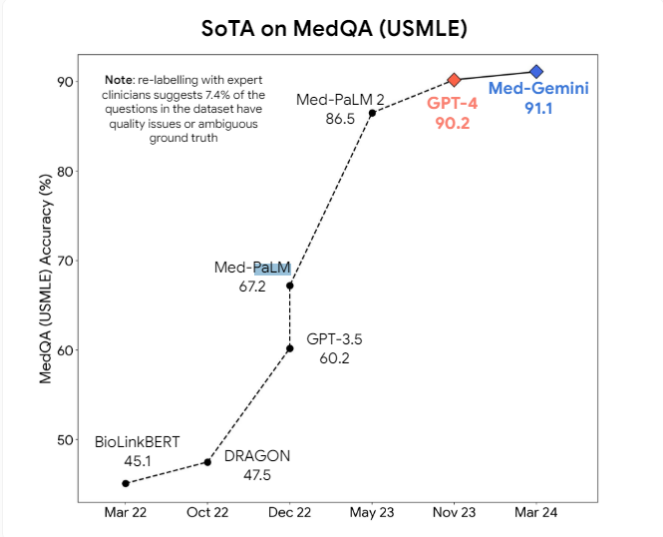
さらに研究者らは、GPT-4vのようなマルチモーダルモデルが視覚的理解をさらに改善する可能性があると提案した。現在、GoogleのMed-PaLM2やMed-Geminiといった専門的な医療AIモデルや、Llama3をベースとしたMetaの医療モデルの開発が活発に行われており、医療業務における汎用モデルを超えることを目指しています。
しかし、専門家らは、医療 AI モデルが実際に広く使用されるまでには長い時間がかかる可能性があると考えています。現在のモデルの誤差空間は医療現場では依然として大きすぎるため、これらのモデルを日常の医療行為に安全に統合するには、推論機能の大幅な進歩が必要です。
この研究は、医療分野における GPT-4 の可能性を示していますが、AI テクノロジーを複雑な医療シナリオに実際に適用するには、まだ継続的に改善する必要があることも思い出させます。将来的には、マルチモーダル モデルとより強力な推論機能が、医療における AI の安全性と信頼性を確保するための重要な改善となるでしょう。